Hands-on Apache Spark tutorial for beginners

Apache Spark is one of the most famous Big Data tools; it aids in the acceleration of data processing applications through parallelization. Today, I'll show you how Spark can help you get more done in less time. This is a beginner's note for those who are just starting off.
Install Apache Spark
Spark is a software of Apache Software Foundation; it has developed based on Hadoop and provided many high-level APIs in Java, Scala, Python and R. There are many installation options out of there. However, this post will show you how to install it and PySpark (Python API for Spark) using docker. This part follows a tutorial from Apache Spark Cluster on Docker (ft. a JupyterLab Interface); it is recommended to read this article for more details.
First, take a look at the figure below, this show how Spark cluster is organized and how to link spark cluster with jupyterlab. We need to build all of these things on top of a simulated HDFS system, so we can create a docker-compose file for the whole system and build this without any complicated installation stuff.
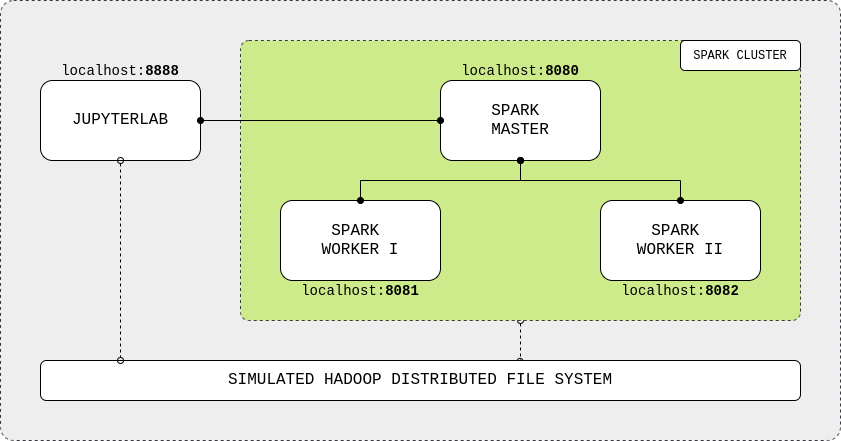
The dockerfile files below are the 4 docker images for HDFS, jupyterlab, spark master and spark worker.
After these image files were declared, we also need a sh script to build all of them.
Finally, we can define our docker-compose file based on the above images.
Now, open your terminal and enter the following commands to complete the installation step.
$ chmod +x build_image.sh
$ ./build_image.sh
$ docker network create spark-network
$ docker-compose up -d
If everything went well, you should be able to access http://localhost:8080/ to inspect your spark cluster
Write your first MapReduce application
The word counting problem is the most well-known and straightforward MapReduce application. In this work, you must create an application that reads a text file and finds the most often occurring word in that file. A simple program will iterate through all text lines sequentially and count the words using a dictionary. You may parallelize this by splitting the dataset into small chunks and sending them to the slave workers for processing and aggregating the results. See the following notebook to know how it works.
As you can see, the MapReduce function employing Spark with 2 clusters is approximately twice as fast as the naive approach. This is what we expected. All code can be found at: https://github.com/vndee/spark-tutorial