What does an AI engineer do?

What exactly does an AI engineer do? It is a common question when I tell my friend I work as an AI engineer. Since each company has a different definition of the role of AI engineer, I don't know how it's like in the others; nonetheless, I can highlight some aspects that may be beneficial based on my experience.
These days, you probably heard about fancy titles like Artificial Intelligence Engineer, Machine Learning Engineer, Deep Learning Engineer, Data Scientist, Data Analyst, etc. The majority of persons with these designations are likely to deal with data. They are hired to play with data and provide valuable insights that can drive the business or an automated solution for resolving the existing business flow bottleneck. What are they doing, though, exactly? What I am talking about here is the actual thing that I have done.
Collect business insights
The first thing that has to be done when we start an AI/ML project is to go and meet some business experts. Make sure you understand the problem correctly and have a shared vision with domain experts. This step is crucial because your project will end in the wrong direction if you cannot do it right.
Project scoping
After knowing what needs to be done, let meet up with technical teams and business teams again. In this phase, you should point out what you can or cannot handle as well as how good it will be. You have to keep in mind that AI/ML is a promising technology, but it is not a magic potion. Business leaders always set high expectations for those technologies, and it's your responsibility to help them realise the possible goals. I have seen many engineers dived into projects with a high expectation of outcomes such as %100\%% accuracy for handwritten text recognition, %90\%% accuracy for stock price prediction, etc. Obviously, they've failed. Do not think it is just the expectation, and you just have to do as best as possible. Remember that you are an engineer, not a researcher, and the industry isn't the same as academia. When a contract is signed, the project goals should be clarified and quantised; if you promise your executives a target you are unsure of, you will put them into a problematic situation.
Planning
Yes, this is a typical part of any software development process. Before doing anything, you need a plan. The planning process is mainly based on your experience. Be sure the time you estimate is enough. Another thing is tech stack. The technical stack is critical; you must imagine which tool, framework, and library will be utilised. For example, if you are a Pythonista, you might be familiar with PyTorch, TensorFlow, Mxnet,.. for training processes, and Flask, FastAPI,.. for deployment processes. Those who want to export a model into an embedded device for high performance may ship the model in ONNX format and use other technologies.

Data collection & analysis
Most of the time in an AI/ML project, you will work with data. You have to translate raw data into usable data that can be used for the modelling stage. Whether you have a small amount of data at the beginning or a large amount of data, it is always an issue. At this step, you must do EDA (explanatory data analysis) to determine whether the data is enough and which features of the data will be used. You must be able to deal with several typical data issues as below:
- Imbalanced class: This is the one I've faced in almost real-life classification tasks. It isn't easy to create an effective classification model for a dataset when almost 90% of the labels belong to one class. Data augmentation, re-sampling datasets, weighting loss, and so on are some approaches that may be useful.
- Sparse dataset: This happens when most of the data you have is %0% or %\text{N/A}%. I've worked in the personalization team at TIKI, and I've spent most of my time working with datasets of user-product interactions. These datasets are sparse; imagine you have a dataset about the 10 million products and 20 million users, and there are only hundreds of million connections between them. Using some basic calculations, you can see that almost the data point with be %0%, which is insufficient if we store these kinds of data as a matrix.
- Quality of the label: This is the most important one when you use supervised learning method. Labels are the instructor of the learning algorithm. Therefore, if the label's quality cannot be controlled, you cannot control the model's outcome. So, It is better to ensure that you fully understand your datasets and know how well it is.
Modelling
At this point, you will decide which kind of algorithm should be used and implement. At the very early version of your project, It is good to avoid complex and heavy state-of-the-art models. You should try the one which is simple enough and possible to provide a baseline version. Thinking simple first is the key. You must also understand the difference between academic research articles and real-world issues. The algorithm's performance may be inconsistent in the different domains, be aware of that.

In most projects, the model training process is important; it will affect the project's outcome significantly. Your responsibility is to implement the algorithm correctly, and thanks to the community, several ML/DL frameworks and libraries (Pytorch, Pytorch-Lightening, Tensorflow, Keras,..) make this job as easy as possible for you. Now all you have to do is design the architecture and train your model using the built-in tools. Oops, did I forget something? Yes, hyper-parameter! Okay, you should seriously pay attention to hyper-parameters such as learning rate, drop-out rate, learning weight decay, or any hyper-parameters given by the model. It will help you fix the issues that arose during the training process.
Deployment
You now have a model ready to deploy after the training process. You will wear a backend engineer's hat at this point and, if required, maybe a DevOps engineer's hat. In most cases, you have to write RESTful API to serve your model. Your API needs to meet the constraints of response time and latency of the production system. The best way to measure the health of an API is using top percentile (TP) measurement.
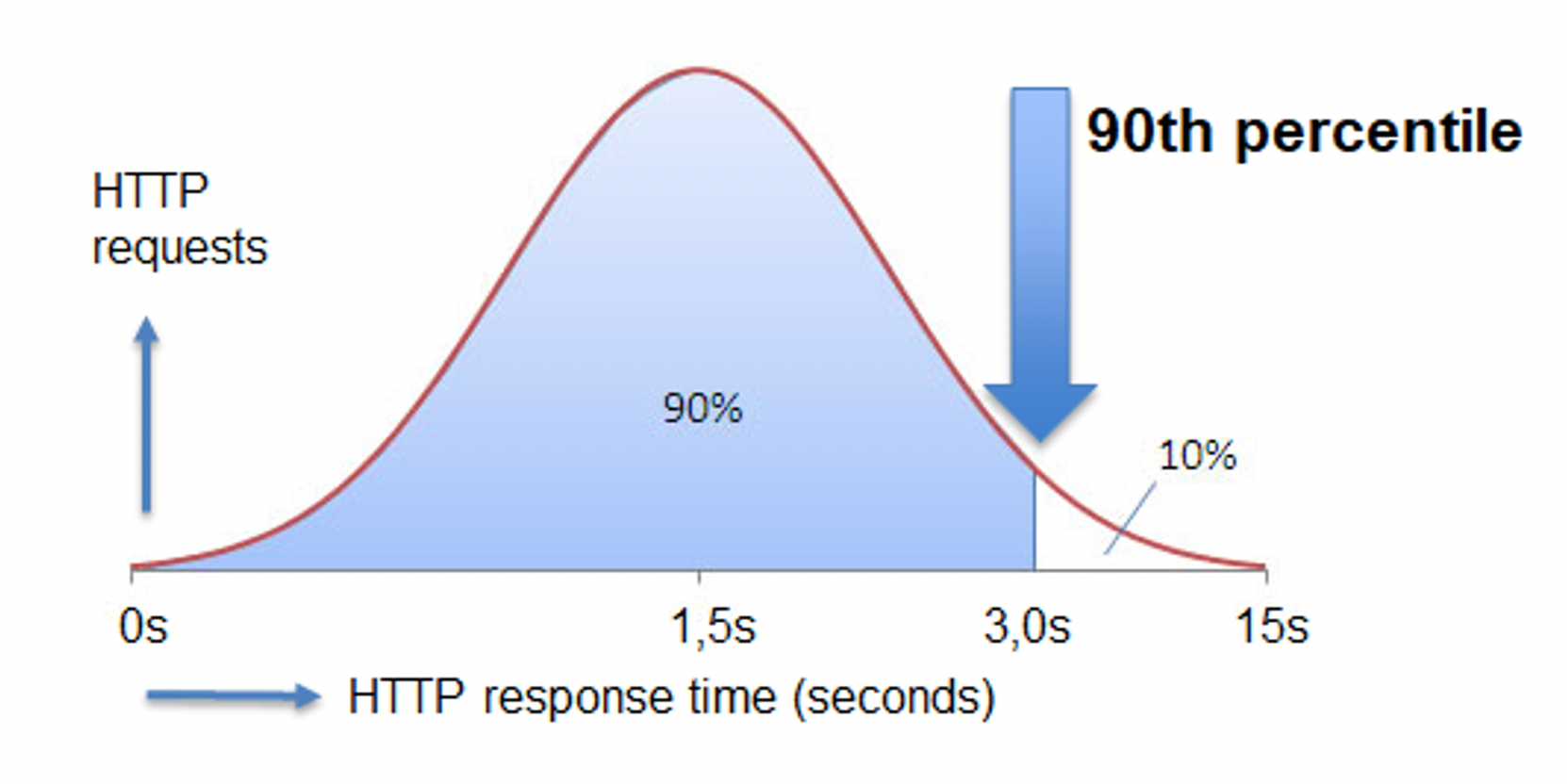
Assume the above-mentioned statistics chart shows the response time distribution of many requests. For example, we have TP90 is the time that %90\%% of the requests were successfully responded. So if our TP90 is %3\text{s}%, we can say that %90\%% of the requests were successfully responded within %3\text{s}%.
Monitoring & evaluation
Once the model was deployed, now you are in charge of the performance of this model in your system. If your model is set to run daily, you must be ensured the running pipeline is working correctly. In this stage, if there are multiple algorithms/models run at the same time. You can use A/B test method to measure which is the good one. After that, you are expected to quickly prototype your solution with immediate user feedback and business needs. Then, gather business insights to help you enhance your solution in the next version.
The project development circle described above is the one I have used in my job. Since each engineer has another approach to solve their problems. My approach is not a standard for everyone. It is simply an example of what an AI engineer actually do in an AI/ML project.