Vẽ vời với AI

TLDR: Copy notebook sau và run, chú ý đoạn add token huggingface:


Cài đặt các thư viện cần thiết:
pip install torch torchvision sentencepiece \
transformers==4.19.2 diffusers \
invisible-watermark huggingface_hub
Tạo tài khoản HuggingFace Hub và sinh access token để download pre-trained model: https://huggingface.co/settings/tokens

Truy cập https://huggingface.co/CompVis/stable-diffusion-v1-4, tick vào "I have read the License and agree with its term", bấm "Access repository" để được cấp quyền access vào pre-trained model.
Login huggingface bằng cách gõ lệnh sau và paste token vừa sinh ỏ trên vào.
huggingface-cli login
git config --global credential.helper store
Khởi tạo mô hình sinh ảnh:
from torch import autocast
from diffusers import StableDiffusionPipeline, LMSDiscreteScheduler
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=True
).to("cuda")
Khởi tạo mô hình dịch Việt-Anh:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer_vi2en = AutoTokenizer.from_pretrained("vinai/vinai-translate-vi2en", src_lang="vi_VN")
model_vi2en = AutoModelForSeq2SeqLM.from_pretrained("vinai/vinai-translate-vi2en").to("cuda")
def translate_vi2en(vi_text: str) -> str:
input_ids = tokenizer_vi2en(vi_text, return_tensors="pt").input_ids
output_ids = model_vi2en.generate(
input_ids.to("cuda"),
do_sample=True,
top_k=100,
top_p=0.8,
decoder_start_token_id=tokenizer_vi2en.lang_code_to_id["en_XX"],
num_return_sequences=1,
)
en_text = tokenizer_vi2en.batch_decode(output_ids, skip_special_tokens=True)
en_text = " ".join(en_text)
return en_text
Hàm sampling:
def sampling(PROMPT):
_prompt_en = translate_vi2en(PROMPT)
print(f"vi: {PROMPT}\nen: {_prompt_en}\n")
with autocast("cuda"):
image = pipe(_prompt_en)["sample"]
from IPython.display import display
display(image[0])
image[0].save("sample.png")
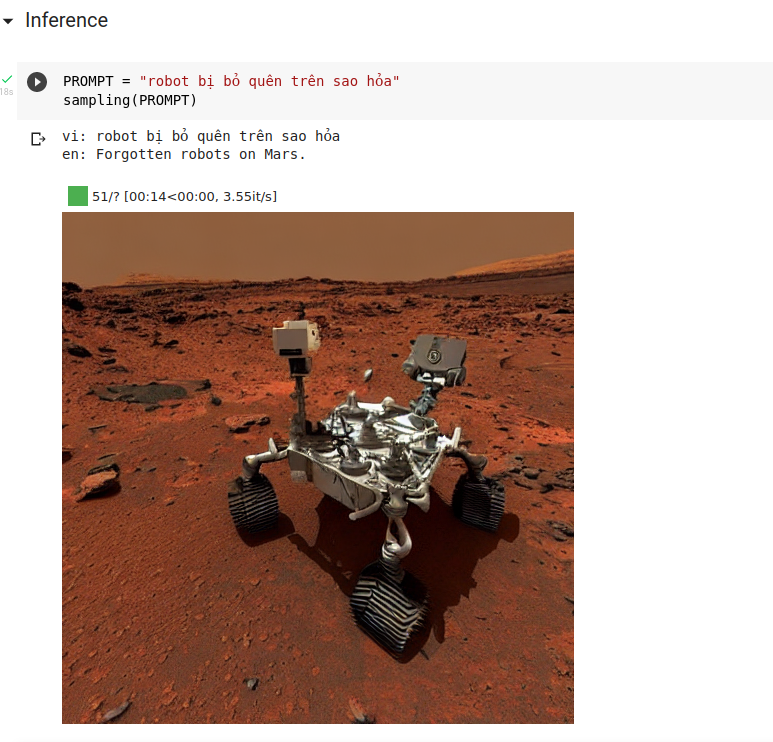
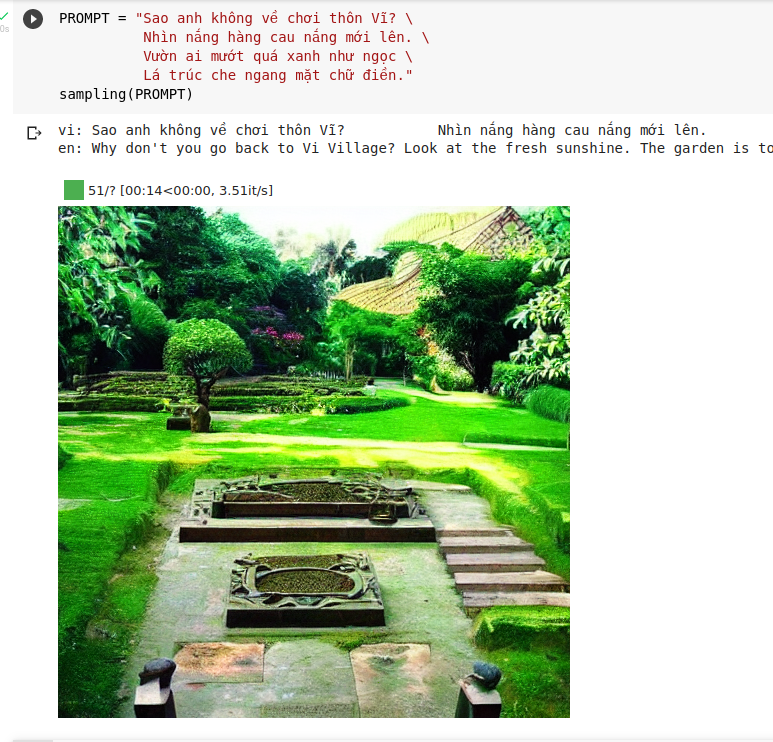
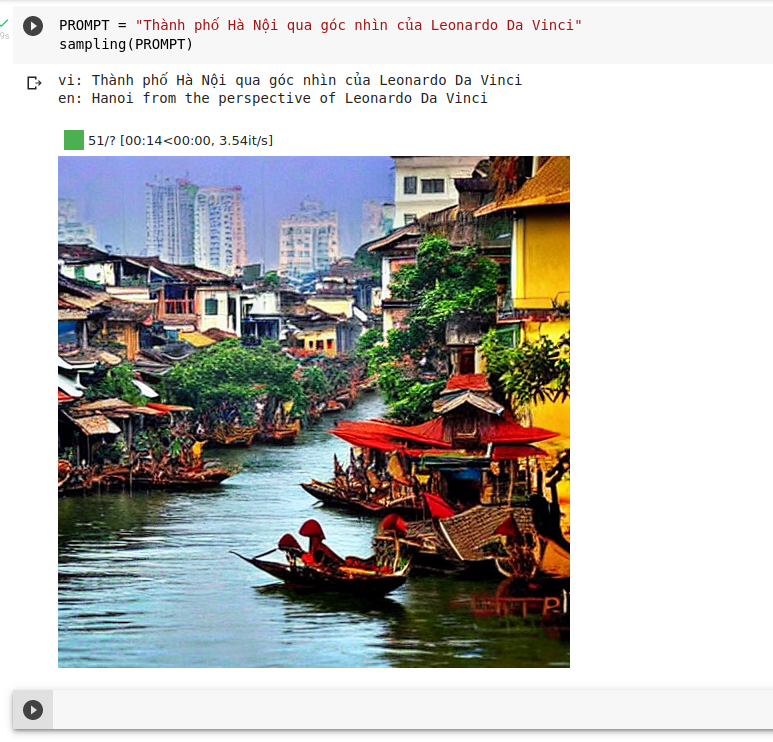
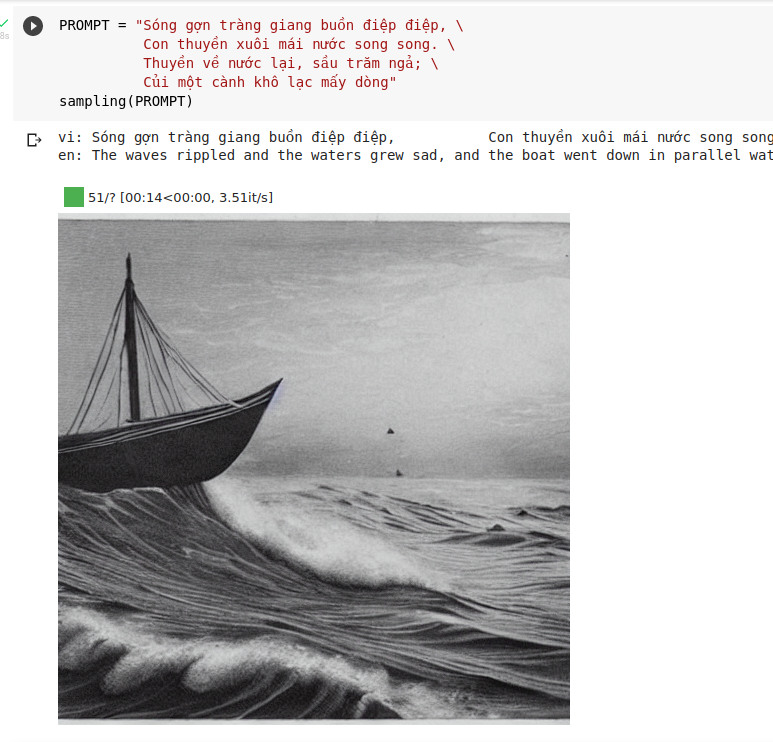
Sau đó dùng hàm sampling để sinh hình ảnh. Ngoài tiếng việt, đương nhiên chúng ta cũng có thể dùng tiếng anh để sinh ảnh chuẩn xác hơn. Tham khảo prompt và kết quả của mô hình này do cộng đồng sáng tạo tại đây: https://lexica.art/
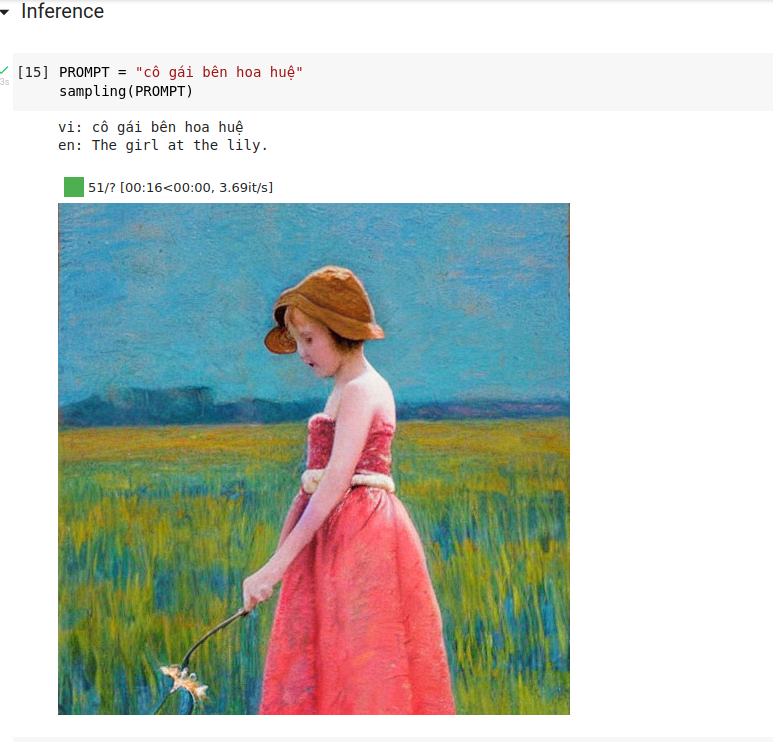
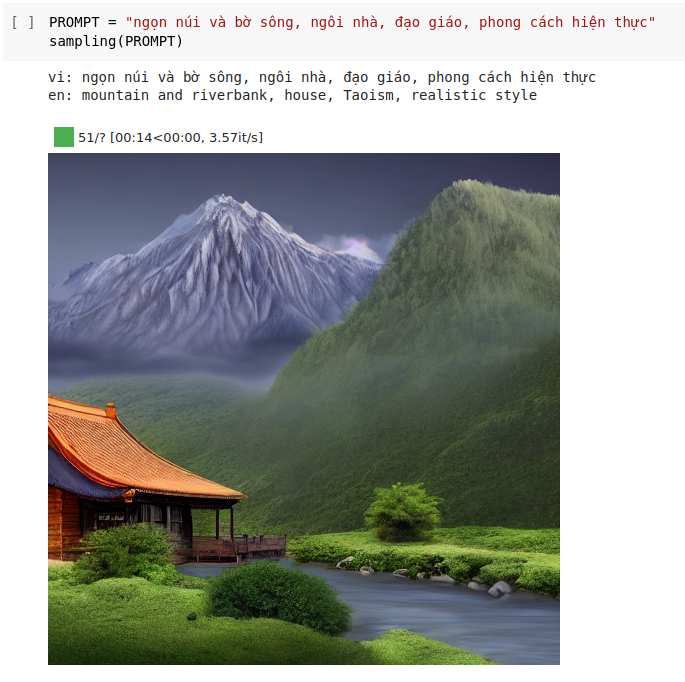
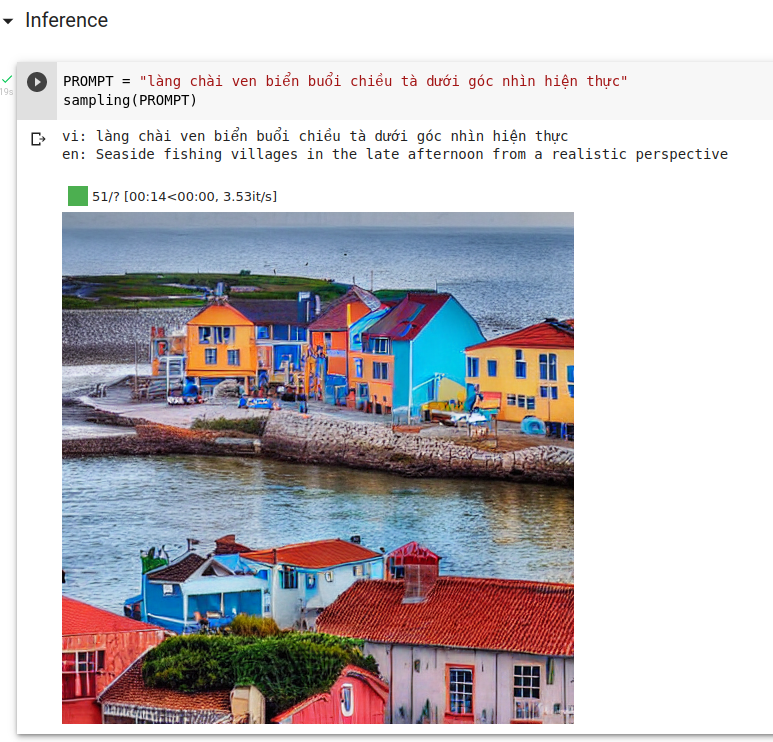
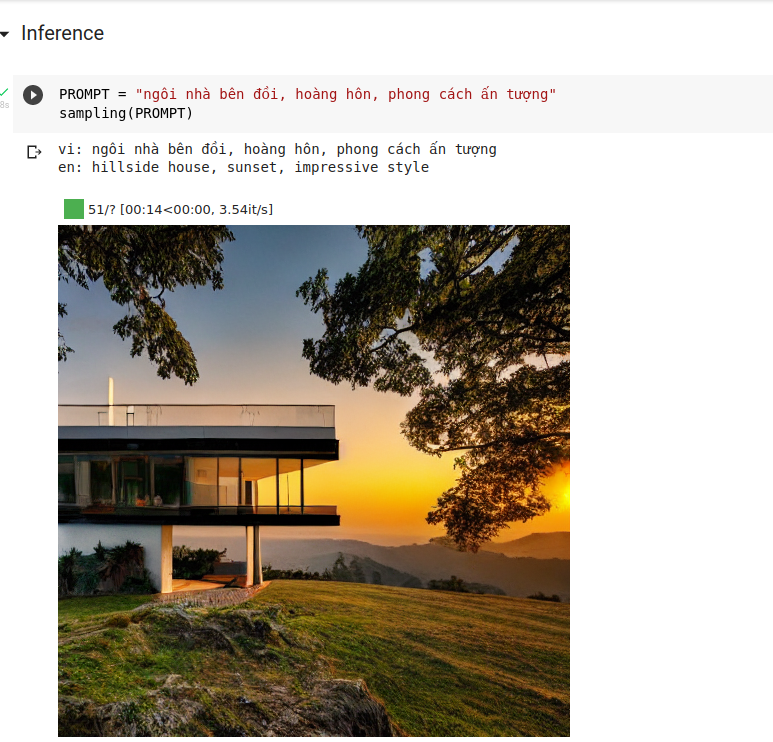
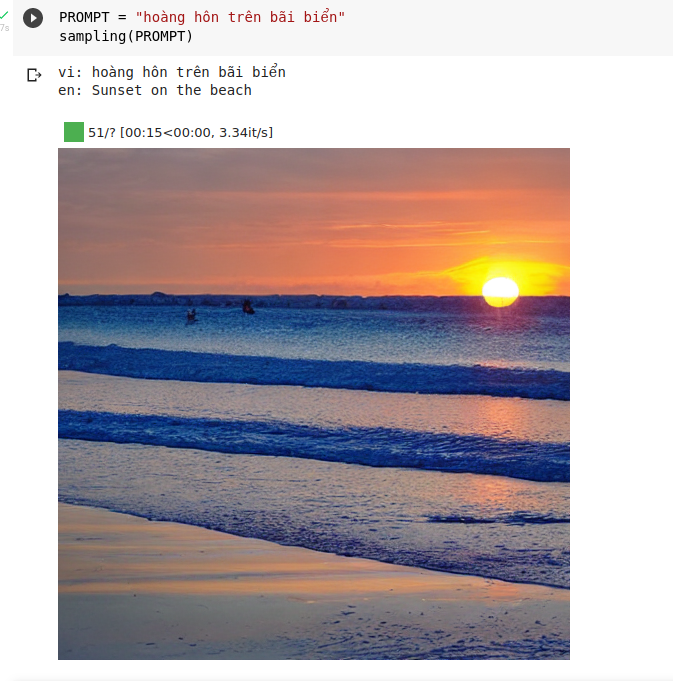

Tham khảo thêm: