The "classic" of Convolutional Neural Network


Neural Network ra đời là một bước đột phá lớn của giới khoa học máy tính và mở ra tìm năng cho các bài toán về thị giác máy tính. Tuy nhiên với những bài toán có dữ liệu đầu vào là hình ảnh thì việc sử dụng mô hình mạng Neural Network truyền thống còn gặp phải nhiều hạn chế. Do đó CNN (Convolutional Neural Network) đã ra đời và trở thành một trong những phương pháp chính để giải quyết các bài toán nhận dạng và phân loại không những trong lĩnh vực thị giác máy tính (Computer Vision) mà còn ở các bài toán về xử lí ngôn ngữ tự nhiên (Natural Language Processing).
Kiến trúc LeNet (1990s)
LeNet là một trong những kiến trúc CNN đầu tiên được đề xuất bởi Yan LeCun sau một loạt các thành công về nghiên cứu bắt đầu từ thập niên 90 của thế kỉ trước.
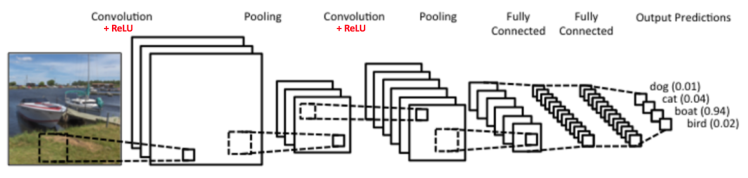
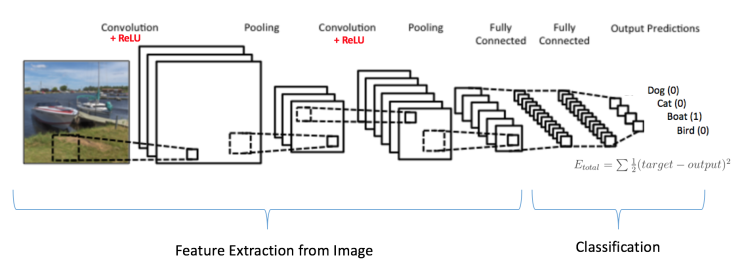
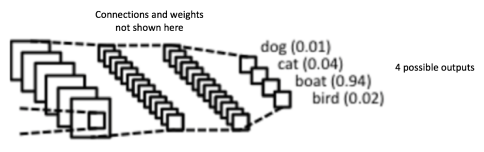
Phía trên là hình ảnh một kiến trúc CNN cơ bản dùng để nhận dạng vật thể trong ảnh. Mạng này lấy ý tưởng từ LeNet kết hợp với một vài cải tiến trong vài năm trở lại đây. Dễ thấy kết quả đầu ra (output) là khá tốt, khi xác suất nhận dạng được có một chiếc tàu (boat) trong ảnh là 0.94. Trong khi với 3 sự lựa chọn còn lại (dog, cat, bird) thì có xác suất khá nhỏ. Điều này đã mô tả đúng ảnh đầu vào (input).
Từ quan sát trên, ta định nghĩa một mạng CNN “kiểu mẫu” sẽ gồm có 4 thành phần như sau:
- Convolution
- Non linearity (ReLU)
- Pooling (Sub Sampling hay Down Sampling)
- Classification (Fully Connected Layer)
Bây giờ chúng ta sẽ xem chi tiết cách mà CNN hoạt động.
Convolution
Convolution hay tích chập chính là tư tưởng chính tạo nên sự khác biệt của CNN so với mạng Neural Network truyền thống. Vậy, tích chập là gì? Theo Wikipedia tích chập của hàm %f% và %g% là một phép biến đổi tích phân đặc biệt với công thức:
$$(f * g)(t)=\int_{-\infty}^{\infty} f(r) g(t-r) d r$$
Dưới góc nhìn thống kê, thì tích chập là kì vọng (Expectation) của của biến ngẫu nhiên với hàm phân phối xác suất cho trước. Để dễ hiểu ta hãy lấy một ví dụ: Giả sử ta cần xác định vị trí của một thiết bị có định vị GPS (để đơn giản ta chỉ xác định kinh độ). Thực tế GPS không bao giờ hoạt động chính xác %100\%%, nghĩa là khi đứng yên thì tọa độ vẫn dao động. Do đó, ta cần một phương thức để ước lượng vị trí hiện tại từ thông tin của các tọa độ ghi nhận được. Ta định nghĩa một hàm %f(x)% là tọa độ của thiết bị GPS ghi nhận được và hàm %g(t−x)% mô tả trọng số của %f(x)% tại thời điểm %t%, %g(t−x)% càng lớn thì độ tin cậy của %f(x)% tại %t% càng lớn. Rõ ràng kết quả mong muốn của chúng ta sẽ là:
$$E=\sum_{\forall x} f(x) g(t-x)$$
Nhưng nếu %f(x)% là một hàm liên tục, ta sẽ có:
$$E=\int_{-\infty}^{\infty} f(x) g(t-x) d x$$
Cho nên có thể thấy tích chập cho ta thấy được sự tương quan giữa hai hàm số hay nói cách khác khi hai hàm số càng giống nhau thì giá trị tích chập càng lớn.
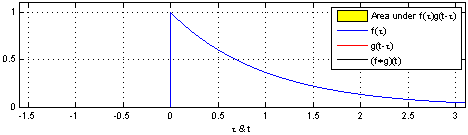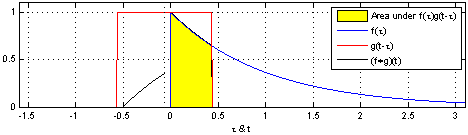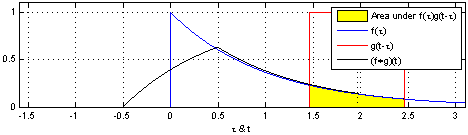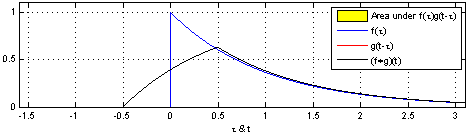
Trở lại với convolution trong CNN, với dữ liệu đầu vào là hình ảnh, không giống như những gì chúng ta thấy khi nhìn vào một bức ảnh. Máy tính sẽ nhìn một bức ảnh như một ma trận các con số có giá trị từ 0 đến 255.
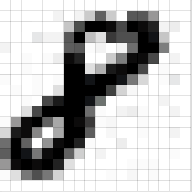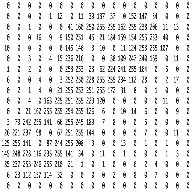
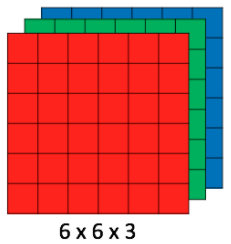
Channel là kênh màu của một bức ảnh, một bức ảnh tiêu chuẩn RGB có ba kênh mà đó là đỏ (red), lục (green) và lam (blue). Cách biểu diễn một bức ảnh RGB trên máy tính là một ma trận %H×W×D% thay vì %H×W% như một bức ảnh grayscale (bức ảnh chỉ có 2 màu là đen và trắng).
Ở Convolutional layer trong kiến trúc CNN, mục tiêu chính của nó là phát hiện đặc trưng từ một bức ảnh cho trước. Đặc trưng ở đây thể hiện mối quan hệ về không gian giữa các pixel trong một tấm ảnh, đó có thể là một đừng thẳng, đường cong, hay một đoạn gắp khúc. Để làm được điều đó ta định nghĩa một filter hay còn gọi là kernel có tác dụng như một sliding window trượt qua toàn bộ bức ảnh và tích chập với từng vùng nó đi qua.

Chúng ta cùng xét một ví dụ:
Cho ma trận %5×5% biểu diễn một ảnh grayscale:

Và một filter kích thước %3×3% như bên dưới:

Sau đó cho filter trượt trên ảnh và tích chập:

Kết quả nhận được là một ma trận %3×3% ở đầu ra. Ma trận này được gọi là Convolved Feature hay Feature Map. Phép tính tích chập trong trường hợp này là tổng element wise giữa hai ma trận cùng kích thước (tổng của tích các ô tương ứng). Vậy câu hỏi đặc ra là làm sao để filter có thế phát hiện được đặt trưng của một tấm ảnh (Feature detection)? Để giải thích điều này ta cũng hay hình dung filter là một tấm ảnh mô tả đặc trưng, ví dụ dưới đây là một filter mô tả đường cong:

Ta cho filter này tích chập với phần góc trái, trên (ô vuông màu vàng) của ảnh gốc.
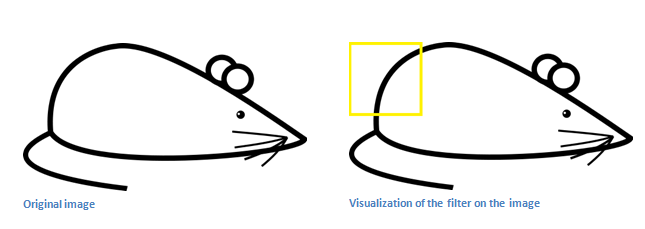
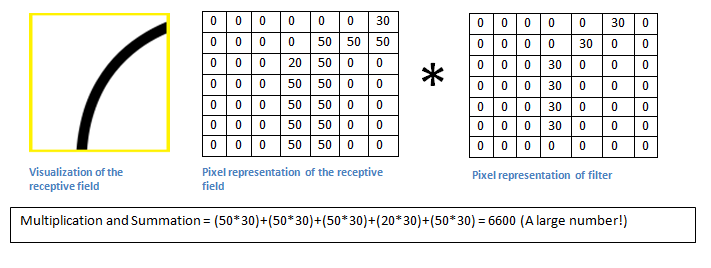
Kết quả phép tính tích chập là %6600%. Bây giờ ta sẽ thử filter lên một vùng khác của tấm ảnh gốc:

Kết quả ở vùng này là %0%. Do đó ta kết luận rằng vùng góc trái, trên của tấm ảnh khớp hơn với filter hay nói cách khác là xác suất có một đường cong như trong filter ở vùng này là rất cao. Tương tự như vậy, ta có thể dùng nhiều filter khác để phát hiện nhiều đặc trưng khác của tấm ảnh để có một cái nhìn tổng quát về nội dung bức ảnh. Ta có một vài ví dụ về các filter phổ biến hiên nay:


Trong thực tế, filter chính là cái chúng ta cần learning. Learning các giá trị của filter sao cho phù hợp với bài toán là mục tiêu của quá trình training CNN. Tuy nhiên vẫn có một số tham số chúng ta cần gán một cách thủ công đó là số lượng filter, kích thước filter, số lượng layer,… Càng nhiều filter thì hình dung về bức ảnh sẽ càng chi tiết và xác suất chính xác sẽ càng cao.
Kích thước của Feature Map
Feature Map hay Convolve Feature phụ thuộc vào 3 yếu tố sau:
- Depth: Độ sâu hay số lượng channel của bức ảnh là yếu tố đầu tiên. Độ sâu của Feature Map nhất thiết phải bằng với số channel. Vì thực chất một bức ảnh RGB sẽ được biểu diễn trên máy tính bằng cách ghép 3 ma trận pixel lại với nhau như đã đề cập ở trên. Vì vậy cho nên cần phải có 3 filter khác nhau cho từng channel.
- Stride: Lẽ dĩ nhiên kích thước bước nhảy ảnh hưởng trực tiếp đến kích thước của Feature Map, cụ thể là chiều dài và chiều rộng.
- Padding: Padding hay Zero-padding liên quan đến vấn đề weight-sharing trong CNN. Ta thấy khi cho filter trượt trên ảnh gốc thì những pixel nằm càng gần tâm của ảnh thì sẽ càng được filter chạy qua nhiều lần còn những pixel ở càng xa (gần biên) thì càng ít được chạy qua. Do đó sẽ xảy ra trường hợp một số thông tin ở giữa tấm ảnh trở nên được “coi trọng” hơn (vì được tính nhiều hơn) là những thông tin bên ngoài. Điều đó thường dẫn đến việc bỏ qua nhiều thông tin quan trọng, vì những thông tin quan trọng không hẳn là luôn luôn nằm ở giữa bức ảnh. Để xử lí điều này, người ta thêm viền ngoài của bức ảnh những thông tin giả là những pixel gồm toàn số %0% để cho các pixel ngoài biên lùi sâu vào trong hơn và đóng góp bình đẳng trong quá trình tính toán.
Đến đây, ta xây dựng được một công thức để tính kích thướng của một Feature Map bất kì:
$$\left(O_h, O_w\right)=\left(\frac{I_h-F_h+2 P_h}{s}+1, \frac{I_w-F_w+2 P_w}{s}+1\right)$$
Trong đó:
- %O% là kích thước Feature Map (high, width).
- %I% là kích thước ảnh input (high, width).
- %F% là kích thước filter (high, width).
- %P% là kích thước padding (high, width).
- %S% là kích thước của bước nhảy.
Non linearity (ReLU)
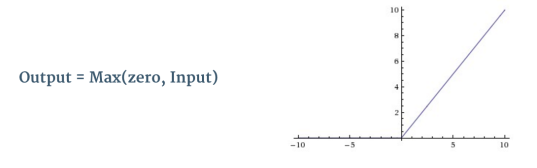
Non linearity hay khử tuyến tính là một vấn đề cần thiết đối với CNN. Đây là một activation layer đi theo sau Convolution layer để lọc các giá trị trong feature map. Có rất nhiều hàm activation có tác dụng làm khử tuyến tính như là sigmoid hay tanh. Tuy nhiên, hàm ReLU (Rectified Linear Unit) được dùng phổ biến nhất đối với CNN vì nó giúp train model nhanh hơn những hàm còn lại và tránh được trường hợp (Vanishing Gradient Problem). Hàm ReLU sẽ fix tất cả những giá trị âm ở Feature Map thành 00 do nó có dạng %f(x)=\text{max}(0,x)%.


Pooling layer
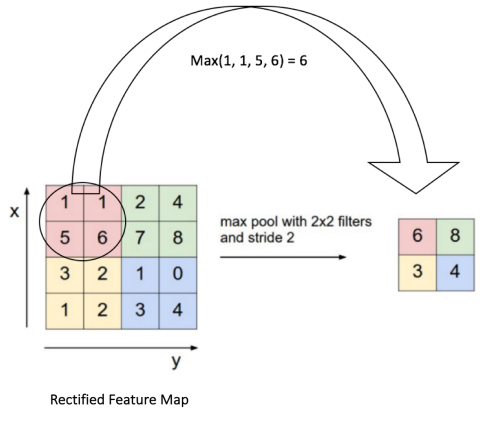
Ngay sau ReLU layer sẽ là pooling layer hay còn gọi là subsamling hay downsampling layer. Mục tiêu của bước này là làm giảm kích thước của tấm ảnh và chỉ giữ lại những thông tin quan trọng giúp kiểm soát overfitting. Những cách cài đặt pooling layer phổ biến là max pooling, sum pooling và avg pooling. Ví dụ, với max pooling layer dưới đây, ta chia Rectified Feature Map thành những ma trân %2×2% và chỉ giữa lại những giá trị lớn nhất trong đó:
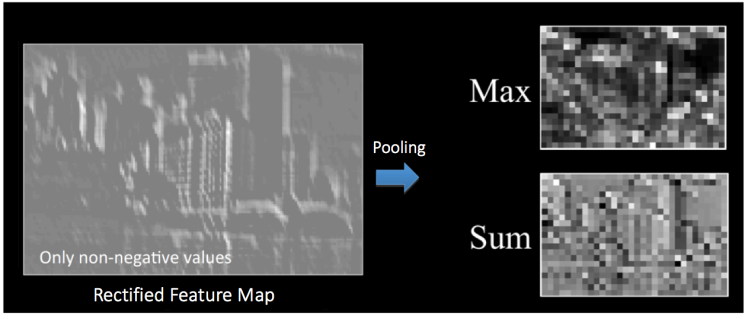
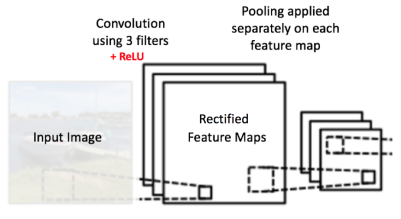
Convolutional block
Tất cả những layer đã trình bày ở trên Convolution, ReLU, Pooling thường sẽ được kết hợp với nhau để tạo thành một Convolutional block. Tùy theo yêu cầu của bài toán, tài nguyên tính toán mà sẽ có nhiều kiến trúc CNN khác nhau gồm một hay nhiều Convolutional block.
Fully Connected Layer
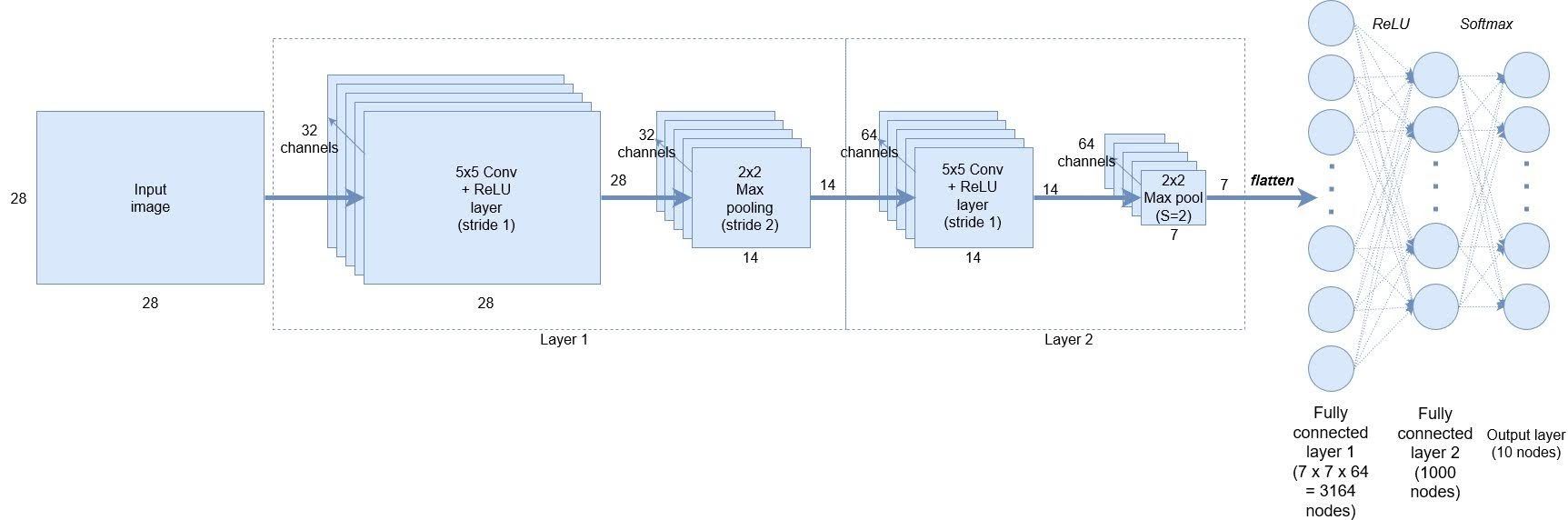
Sau bước convolution, ta đã có được một output gồm các feature đã trích ra được từ ảnh gốc. Công việc còn lại đó là dùng những đặc trưng đó để phân loại và đưa ra kết quả.
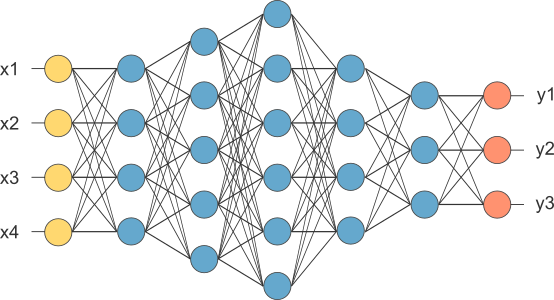
Để làm được như vậy, ta flatten data và sử dụng lại mạng Neural Network truyền thống với input là các feature có được từ Convolution layer và output là một softmax layer.
Training
Sau khi đã tìm hiểu về kiến trúc của Convolutional Neural Network. Chúng ta sẽ đến bước training, cũng như nhiều mạng Neural Network khác ở đây ta cũng dùng Backpropagation để training. Tiến trình training có thể thực hiện như sau:
- B1: Khơi tạo tất cả các tham số một cách ngẫu nhiên.
- B2: Nhận ảnh đầu vào thực hiện feed-forward (lan truyền tiến) và tính đầu ra cho softmax-layer. Do các tham số được khởi tạo ngẫu nhiên cho nên xác suất nhận được ở softmax-layer cũng là ngẫu nhiên.
- B3: Tính hàm mất mát (loss function): %\text{TotalError}=\sum{\frac{1}{2}(\text{target_probability}−\text{output_probability})}%
- B4: Dùng backpropagation để tính gradient và update các tham số.
- B5: Lập lại B2 -> B4 với tất cả các training set.
Ví dụ với Keras và Fashion-MNIST
Fashion-MNIST
Có lẽ bộ dữ liệu chữ số viết tay MNIST đã quá đổi quen thuộc với chúng ta, đến nỗi nhàm chán. Có nhiều người cho rằng MNIST đã trở nên quá dễ khi có nhiều model đạt độ chính xác gần %99\%%. Khiến cho việc đánh giá giữa các model trở nên khó khăn khi dùng MNIST. Gần đây cũng đã có một version mới của MNIST đó là EMNIST. Trong khi đó, Zalando Research Team cũng đã public Fashion-MNIST. Fashion-MNIST gồm 60000 training images và 10000 training images thuộc 10 classes khác nhau: T-shirt/top, trouser, pullover, dress, coat, sandal, shirt, sneaker, bag, ankle boot. Chúng ta hãy thử cài đặt CNN với keras và Fashion-MNIST.
Đầu tiên là import các thư viện cần thiết và thiết đặt các thông số training cơ bản:
Chuẩn bị dữ liệu: Tất cả các hình ảnh từ Fashion-MNIST đều là các ảnh grayscale có kích thước %28×28%. Fashion-MNIST có thể download trực tiếp từ Keras.
Normalize ma trận pixel về kiểu các số float32 từ 0 đến 255. Và in ra thông tin của dataset:
Định nghĩa một CNN model với 2 convolutional layers và một fully connected layer.
Định nghĩa hàm mất mát cross-entropy và dùng Adam optimizer, ngoài Adam chúng ta cũng có thể dùng SGD (Stochastic gradient descent).
Tiếp theo là bước training model:
Test model
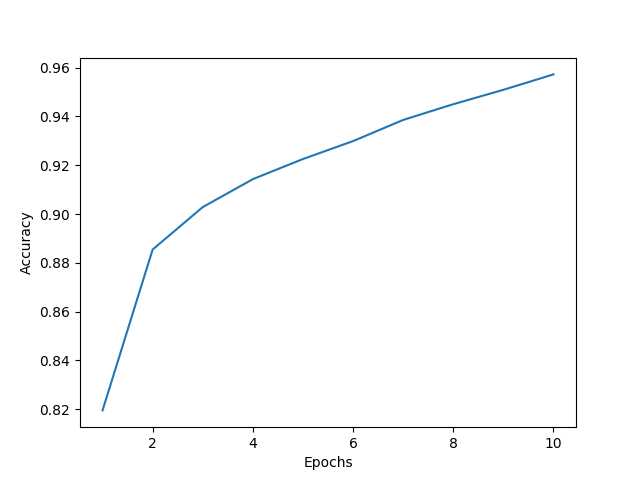
Kết quả cho thấy mô hình đạt độ chính xác khá cao chỉ sau 10 lần training (%91.66\%%). Ta có thể so sánh với một số classifier khác tại Fashion-MNIST Benchmark.

Tài liệu tham khảo và bản quyền hình ảnh
- An Intuitive Explanation of Convolutional Neural Networks
- CS231n Convolutional Neural Networks for Visual Recognition: ConvNets Note
- Understanding of Convolutional Neural Network (CNN) — Deep Learning
- A Beginner’s Guide To Understanding Convolutional Neural Networks
- Keras tutorial – build a convolutional neural network in 11 lines