System Availability
In the world of system design, one of the most critical attributes that most architects aim to achieve is availability. Availability refers to the ability of a system to remain operational and accessible to users even in the face of various failures, disruptions, and maintenance activities. Ensuring high availability is paramount, as it directly affects the user experience and business continuity. This blog post will explore key strategies and considerations for achieving exceptional availability in real systems.
Redundancy & Fault Tolerance
Redundancy is a fundamental concept in system design to ensure availability. Redundancy involves having backup components or systems in place to take over in case of failure. This redundancy can be applied to various parts of a system, such as servers, databases, network connections, or power supplies. The idea is that if a critical component fails, the redundant one can seamlessly take over, minimizing downtime and ensuring continuous service.
For example, in a web server cluster, multiple servers can serve the same application, and if one server fails, user requests can be automatically routed to another functioning server. Similarly, in data storage, data can be replicated across multiple servers or data centers to ensure data availability even in the event of hardware failures.
- Server Redundancy: Employing multiple servers for the same service, often in a load-balanced configuration, ensures that even if one server fails, the others can handle the incoming traffic.
- Data Redundancy: Data is a critical asset. Storing it redundantly, often in multiple data centers or regions, helps prevent data loss due to hardware failures, disasters, or other unforeseen events.
Fault Tolerance complements redundancy by enabling a system to continue operating even when components fail. Strategies for fault tolerance include:
- Self-healing Systems: Systems can be designed to detect issues and automatically recover. For instance, if a service within a cluster crashes, an orchestrator can detect the failure and automatically restart the service on a healthy server. This proactive approach to system management reduces the need for manual intervention and minimizes downtime.
- Graceful Degradation: If a system can't function at full capacity, it should degrade gracefully, providing some level of service instead of a complete outage. For instance, if a video streaming service experiences issues, it might lower the video quality rather than abruptly cutting off the stream, allowing users to continue their viewing experience.
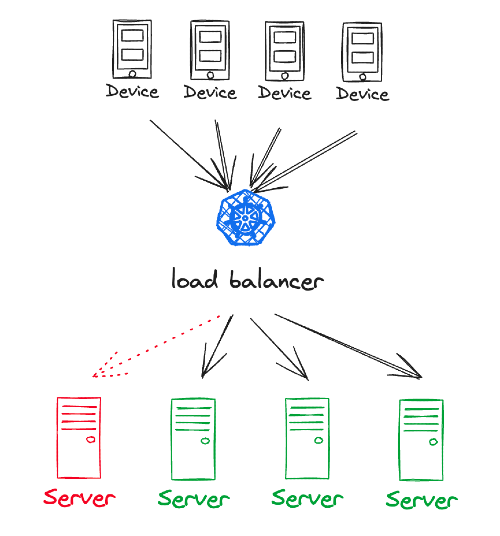
Failover Mechanisms
Failover mechanisms are designed to ensure that the system can automatically switch to a redundant or standby system when the primary system encounters a failure. Failover mechanisms are, at their core, all about ensuring that when something goes wrong, the system can switch seamlessly to an alternate, redundant, or standby system. The process of failover typically involves:
- Health Monitoring: Continuous monitoring of the health and performance of critical components, services, or resources in the system. Anomalies, such as server unresponsiveness, high error rates, or resource exhaustion, are promptly detected.
- Automatic Triggering: When the monitoring system detects a critical issue or anomaly in the primary system, it automatically triggers the failover process. This process should be as swift and seamless as possible, often involving minimal human intervention.
- Promotion of Standby Systems: In a failover scenario, standby or redundant systems are promoted to take over the duties of the failing or failed primary system. This is particularly common in scenarios involving database clusters, where a standby database server can swiftly assume the primary role.
For example, we can consider two common types of failure: Database and Service failover.
Database Failover
Database clusters are prime candidates for failover mechanisms. Databases hold critical data, and downtime or data loss can have severe consequences. Implementing automatic database failover minimizes these risks:
- Automatic Role Promotion: In a database cluster, if the primary database server encounters a failure, an automatic failover mechanism promotes one of the standby servers to assume the role of the primary. This ensures that the application can continue to operate with minimal disruption, often with minimal or no data loss.
- Data Replication: To enable this smooth transition, data replication is crucial. The standby servers must be continuously synchronized with the primary to ensure they have the most up-to-date data. This can involve various replication methods, such as synchronous or asynchronous replication.
Service Failover
Failover mechanisms are not limited to databases; they extend to services as well. Services should be designed to handle failover gracefully, and load balancers often play a crucial role in this:
- Load Balancers: Load balancers are the traffic directors of a system. They continually monitor the health of service instances and distribute incoming requests among them. If a service instance becomes unhealthy or unresponsive, the load balancer can automatically divert traffic to healthy instances, ensuring that users experience minimal disruption and downtime.
Reliable Cross-System Communication
Reliable cross-system communication is essential to maintain high availability. Systems are often composed of multiple components that need to exchange data and messages. This communication must be designed to be resilient and fault-tolerant.
To achieve reliable cross-system communication, engineers can implement practices such as message queuing, circuit breakers, and protocol-level retries. These mechanisms help ensure that data is not lost and that services can continue to function even when parts of the system experience temporary disruptions.
In a distributed architecture where services are often loosely coupled and may be scattered across different networks or even geographical locations, the communication fabric binding them together must be robust and fault-tolerant. There are multiple strategies to maintain reliable cross-system communication as follows:
Message Queue
One of the most effective patterns for ensuring reliable communication is the use of message queues. Message queues act as intermediaries between service producers and consumers, providing a buffer that decouples the services.
- Guaranteed Delivery: Message queues can guarantee the delivery of messages even when the consumer is down or busy. This is achieved by storing messages until the consumer can process them, ensuring no message is lost.
- Load Leveling: They help in load leveling by absorbing sudden spikes in requests that the consumer might not be able to handle all at once.
- Ordering and Sequencing: Some message queues can also ensure that messages are processed in the order they were sent, which is critical for certain applications.
Circuit Breakers
A circuit breaker is another pattern that is particularly useful in preventing system failures from cascading. It works similarly to an electrical circuit breaker:
- Failure Detection: When the system detects that a particular service is failing to handle requests, the circuit breaker trips.
- Service Isolation: The tripping of the circuit breaker prevents further requests from reaching the failing service, allowing it to recover and preventing the failure from affecting other services.
- Gradual Recovery: After a cool-down period, the circuit breaker allows a limited number of test requests to pass through to the service. If these are handled successfully, the circuit breaker resets, and normal operation resumes.
Protocol-Level Retries
Retries can be implemented at the protocol level to enhance the resilience of communication:
- Intelligent Retries: Rather than blindly retrying failed operations, intelligent retry mechanisms can assess the nature of the failure. If the failure is likely transient, such as a temporary network glitch, the system can retry the request.
- Backoff Strategies: To prevent overloading the system with repeated retries, a backoff strategy can be implemented. This typically involves waiting longer and longer between each retry, giving the system some breathing room to recover.
Service Rate Limiting
To further ensure system stability, Service rate limiting is a must-have:
- Fair Usage: Rate limiting ensures that no single consumer can monopolize the service resources, enforcing fair usage across all consumers.
- Maintaining Quality of Service: By limiting the number of requests a service can handle, it helps to maintain a predictable quality of service even when demand is high.
- Preventing Abuse: Rate limiting can also protect against abuse or attacks, such as Distributed Denial-of-Service (DDoS) attacks.
Maintenance Without Downtime
Maintenance is an inevitable part of managing systems. However, downtime during maintenance can be detrimental to user experience and business operations. Achieving high availability demands that engineers implement strategies that allow them to perform maintenance tasks without causing disruptions. Here, we'll explore some of these techniques:
Blue-Green Deployment - Traffic Switching
Blue-green deployment is a strategy where you maintain two identical environments: one is the "blue" environment (the current production version), and the other is the "green" environment (the new version). This approach facilitates seamless updates:
- Isolation of Environments: Blue and green environments are kept isolated and run independently. The blue environment serves live traffic, while the green environment is used for testing and updates.
- Zero-Downtime Switch: To perform an update, you switch traffic from the blue environment to the green environment. This transition can be almost instantaneous, ensuring minimal or no downtime.
- Testing and Validation: Updates are first rolled out to the green environment, where they are thoroughly tested. Any issues can be addressed before directing live traffic to the green environment.
- Quick Rollback: If issues arise after the switch, reverting to the blue environment is quick and straightforward.
Canary Releases - Gradual Testing
Canary releases are a cautious approach to updates, where you roll out new versions to a small subset of users or a limited portion of your infrastructure. This enables you to monitor and validate the changes gradually:
- Initial Release: Initially, the new version is released to a small, carefully selected group of users or a subset of the system.
- Monitoring and Feedback: During this phase, closely monitor the performance and gather user feedback. Look for any issues or unexpected behavior.
- Gradual Expansion: If the new version performs well, gradually expand its release to a larger user base or more components. Continue monitoring and collecting feedback.
- Full Rollout: Once you're confident in the update's stability and performance, proceed with a full rollout.
- Safety Measures: Canary releases allow for the containment of potential issues to a limited audience, reducing the impact of problems and providing an opportunity to address them before wider deployment.
Defining and Measuring Availability
Service Level Agreements (SLA), Service Level Indicators (SLI), and Service Level Objectives (SLO) are essential components of a robust availability strategy. These terms are used to define, measure, and guarantee the availability of a system.
Service Level Agreements (SLA)
An SLA is essentially a contract between a service provider and the end-user that lays out the terms of service delivery. It's the promise of availability and performance that a service provider makes to its customers.
- Uptime Guarantees: SLAs often define the expected availability in terms of uptime, typically expressed as a percentage (e.g., 99.9% uptime).
- Downtime Concessions: It also details the repercussions of failing to meet these standards, which could include compensations or service credits.
- Scope of Service: SLAs cover various aspects of the service, from support response times to maintenance windows, providing a comprehensive view of what the users can expect.
Service Level Indicators (SLI)
SLIs are the measurable values that indicate the level of service being provided. They are the metrics through which the health and performance of a service can be assessed.
- Response Times: This SLI measures how quickly the system responds to requests. It's critical because even if a service is up, slow responses can be as bad as outages.
- Error Rates: This is a measure of the rate at which service requests fail. These can be full outages or partial degradation of service.
- Uptime/Downtime: This metric tracks the actual performance of the service against the SLA's uptime commitment.
Service Level Objectives (SLO)
SLOs are specific targets set by service providers, based on SLIs, for the level of service they aim to provide. They represent the goals that the service provider is striving to achieve.
- Quantifiable Targets: SLOs provide tangible targets, such as "the service will be available 99.95% over 30 days."
- Benchmarks for Success: They serve as benchmarks to determine whether the service is living up to the expectations set in the SLA.
- Focus for Improvement: SLOs also help in identifying areas where the service needs improvement. If an SLO is consistently not being met, it's a clear sign that some aspect of the system needs attention.
In essence, SLA, SLI, and SLO are not just acronyms; they are the cornerstone of a trust relationship between service providers and users. They form the basis of a strategic approach to achieving and maintaining the high availability that is critical in today’s digital landscape. Together, they provide a clear path for ensuring that services remain reliable, available, and performant, thereby creating a better experience for the user and a more manageable and predictable environment for the service provider.
Conclusion
In conclusion, designing for availability is a multifaceted task that involves redundancy, failover mechanisms, reliable cross-system communication, maintenance strategies, and robust SLAs, SLIs, and SLOs. Ensuring high availability is crucial for businesses and services in today's digital world, and a well-designed system that prioritizes availability can lead to better user experiences, increased revenue, and improved overall reliability.