Recommendation system thực chiến

Với sự phát triển mạnh mẽ và bùng nổ chưa từng có của xu hướng tiêu dùng trực tuyến như hiện nay. Cuộc chơi dịch vụ số đang trở nên khốc liệt hơn bao giờ hết. Vì vậy, việc tối ưu hóa trải nghiệm để giữ chân người dùng là nhiệm vụ quan trọng hàng đầu của các nền tảng phát triển nội dung số. Các big-tech lớn như FAANG (Facebook, Amazon, Apple, Google, Netflix, Google) hay tay chơi mới nổi Tiktok đã và đang rất thành công trong việc này bằng cách sử dụng những công nghệ khuyến nghị (recommendation) thông minh. Chúng ta luôn tự hỏi vì sao mình lại bị cuốn vào Facebook, Tiktok, Instagram một cách dễ dàng đến vậy. Làm sao các nền tảng này có thể chọn lọc những nội dung phù hợp cho từng người giữa hàng triệu hoặc thậm chí hàng tỉ nội dung được tải lên các nền tảng này mỗi ngày. Với một chút trải nghiệm khi từng tham gia xây dựng hệ thống khuyến nghị sản phẩm tại Tiki, mình sẽ vẽ lại một phần bức tranh trên. Bức tranh về nền tảng công nghệ đằng sau thành công của những hệ thống khuyến nghị. Đương nhiên là sẽ có khác biệt về cách vận hành những hệ thống khuyến nghị cho từng loại nội dung khác nhau, tuy nhiên nền tảng công nghệ phía sau về cơ bản là gần giống nhau. Vì vậy, case-study về thương mại điện tử cũng là một ví dụ khá điển hình.
Mục tiêu
Đầu tiên ta cùng xét đến mục tiêu của một hệ thống khuyến nghị. Thành công lớn nhất của một hệ thống khuyến nghị sản phẩm đó là cá nhân hóa hoàn toàn trải nghiệm của khách hàng trên nền tảng trực tuyến. Điều đó có nghĩa với những người dùng khác nhau truy cập vào nền tảng, chúng ta sẽ cung cấp những nội dung khác nhau. Với hi vọng những nội dung đó phù hợp với sở thích cũng như hành vi tiêu dùng của khách hàng. Từ đó sẽ tăng tỉ lệ mua hàng, tăng doanh thu và giảm chi phí marketing.

Vấn đề dữ liệu
Để đạt được những mục tiêu trên, trước hết chúng ta phải có cách để định danh khách hàng và ghi nhớ lịch sử hành vi của họ trên nền tảng. Do đó, thành phần quan trọng đầu tiên của hệ thống khuyến nghị chính là tracking system. Ví dụ với trường hợp của TIKI, hệ thống tracking sẽ chịu trách nhiệm ghi nhận toàn bộ hoạt động của người dùng trên nền tảng web và app của tiki như: open app, click, view, add to cart, purchase, cancel order,... để lưu vào data warehouse. Điều đặc biệt tất cả những thông tin này phải được gắn với một định danh người dùng xác định. Chẳng hạn, khi ta cần kiểm tra xem ông A đã thực hiện những hành động gì trên TIKI vào ngày 12-06-2022 thì ta có thể dễ dàng truy vấn ra bản ghi như sau:
| timestamp | customer_id | event | product_id |
|---|---|---|---|
| 00:55:23 12-06-2022 | ONG_A | view | 123456 |
| 00:57:41 12-06-2022 | ONG_A | add-to-cart | 123456 |
| 12:01:15 12-06-2022 | ONG_A | purchase | 123456 |
Trong trường hợp đơn giản nhất khi khách hàng đã đăng nhập vào hệ thống, thì việc định danh event là hoàn toàn dễ dàng. Tuy nhiên, chúng ta cũng không muốn mất đi một lượng khách hàng tiềm năng khá lớn đó là khách hàng đã vào TIKI tìm kiếm và duyệt sản phẩm nhưng vẫn chưa quyết định đăng ký tài khoản và mua hàng. Hay những khách hàng đến thông qua các nền tảng quảng cáo như Facebook Ads, Google Ads, Tiktok Ads hoặc các chương trình tiếp thị liên kết (affiliate). Việc định danh được những người dùng này sẽ giúp tăng hiệu quả những chiến dịch marketing về sau, đặc biệt là những chiến dịch re-targeting, giúp ích rất nhiều cho việc khai thác tập khách hàng tiềm năng. Thật may mắn, ở một mức độ chấp nhận được, các công cụ kỹ thuật như cookie, device_id, mac_address,.. có thể giúp các kỹ sư làm được việc này.
Một vấn đề khác cần lưu tâm khi thu thập dữ liệu đó là session. Session chính là một phiên hoạt động của người dùng trên nền tảng. Việc tách các session là rất quan trọng, bởi vì sự liên kết giữa một chuỗi các hành động được thực hiện liên tiếp của người dùng chính là thứ chúng ta muốn tìm kiếm. Chúng ta muốn tìm ra những quy luật hành vi đó để giúp cải thiện customer journey. Ví dụ như bản ghi của ông A ở trên, ta thấy 2 event view và add-to-cart product 123456 chỉ cách nhau hơn 2 phút (00:55:23 12-06-2022 và 00:57:41 12-06-2022). Tuy nhiên, phải đến 12:01:15 12-06-2022 thì ông A mới quyết định mua sản phẩm này. Do đó, đây có thể xem là 2 session khác nhau, chúng ta cần phải tìm hiểu xem vì sao khách hàng lại suy nghĩ lâu như vậy rồi mới quyết định mua. Nếu cần thiết phải rút ngắn thời gian chốt đơn thì có thể gửi voucher freeship hay discount 5\% ngay khi ông A bấm add-to-cart chẳng hạn. Lại một câu hỏi hóc búa nữa đó là nếu ông A nhìn thấy sản phẩm yêu thích trong phần quảng cáo của facebook mobile app, sau đó ông A mở máy tính lên và vào trang web TIKI để xem và mua sản phẩm đó thì đây có nên xem là một session hay không? Và nếu có thì phải làm thế nào để group 2 session ở 2 device khác nhau? Bài viết sau mô tả cách mà các kỹ sư của TIKI đã giải quyết một phần câu hỏi đó: How To Deal With Cross Device Sessions in Realtime at Scale.

Trở ngại lớn nhất của một hệ thống tracking đó chính là quá trình scale-up. Với đặc tính real-time, hệ thống phải có khả năng ghi nhận hàng triệu đến hàng tỉ event mỗi ngày và các event phải được ghi nhận ngay lập tức khi nó xảy ra. Để thiết kế được một hệ thống như vậy không phải là một điều đơn giản. Đó chỉ mới là những trở ngại về mặt kỹ thuật. Còn một số trở ngại khác khi xây dựng nền tảng cơ sở dữ liệu người dùng đặc biệt là chính sách về dữ liệu và quyền riêng tư, không phải khách hàng nào cũng cho phép ứng dụng ghi nhận lại hành động của mình dù trên bất kỳ nền tảng nào. Tiếp theo đó là những thông tin ta thu được từ hệ thống tracking hoàn toàn là những dữ liệu định lượng (quantitative data). Còn một loại dữ liệu khác mà hệ thống tracking rất khó có thể thu thập đó là dữ liệu định tính (quanlitative data). Đối với những dững liệu dạng này, chúng ta cần có những phương pháp khác để thu thập.
Phân tích dữ liệu
Có dữ liệu xong thì làm gì? Đó là câu hỏi trọng tâm của bài viết này. Như đã nêu, mục tiêu của chúng ta cá nhân hoá trải nghiệm người dùng. Cho nên sau khi đã có dữ liệu, thì việc tiếp theo cần làm đó là lập một "hồ sơ" cho mỗi người dùng (user profile). Bản profile này mang tính đại diện cho người dùng khi tương tác với hệ thống, một hệ thống đủ thông minh sẽ biết cách tương tác thích hợp với từng loại profile khác nhau.
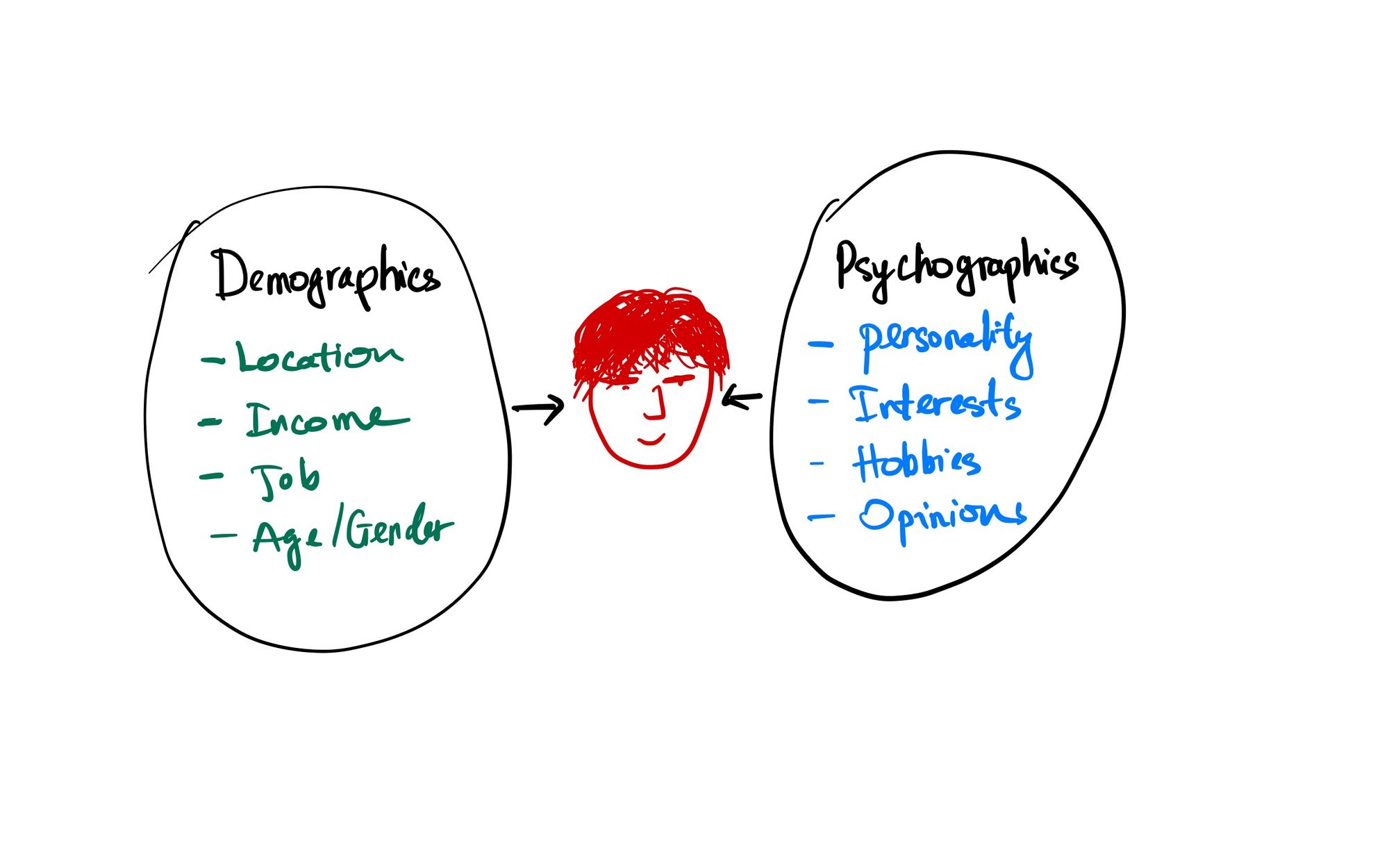
Như chúng ta đã thấy, có 2 nhóm thông tin chính trong profile của người dùng là demographics và psychographics. Những thông tin nhân khẩu học như location, income, job, age, gender,.. thì chắc chắn phải lấy từ những thông tin mà khách hàng đã khai báo khi đăng ký tài khoản hoặc nếu không thì có thể map từ một cơ sở dữ liệu của bên thứ ba nào đó (!?). Hiện nay vẫn có một số phương pháp nội suy ra những thông tin này từ dữ liệu thu thập, tuy nhiên độ tin cậy là không cao. Còn psychographics là những thông tin chúng ta đặc biệt quan tâm. Bởi vì đây thường là những thông tin không có sẵn mà bắt buộc phải suy luận từ dữ liệu. Mặt khác do các đặc tính tâm lý học thường được biểu hiện ra hành vi, mà hành vi chúng ta quan tâm là hành vi trực tuyến - đó là những thứ mà hệ thống tracking đã ghi nhận được. Cho nên chúng ta sẽ tập trung phân tích nhóm dữ liệu này.
Kết quả của quá trình thực hiện phân tích chuyên sâu chính là những analytical report. Những báo cáo này cho phép chúng ta có cái nhìn từ tổng quan đến chi tiết về bức tranh khách hàng. Dựa vào những bức tranh đó, chúng ta có thể quyết định xem nên có những chiến dịch quảng cáo, marketing, giảm giá như thế nào cho phù hợp với từng đối tượng cũng như phân khúc khách hàng. Đây có thể coi là phương pháp khuyến nghị đơn giản mà hiệu quả cao. Chỉ có điều, phương pháp này cho ra kết quả chưa đủ mịn, chưa đủ để cá nhân hoá trải nghiệm của từng khách khách riêng biệt. Thông thường, mức độ của những phân tích này chỉ đạt đến mức độ của các nhóm đối tượng mà thôi.

Khuyến nghị tự động
Khác với hình thức khuyến nghị sản phẩm bằng các phương pháp phân tích dữ liệu cơ bản như trên. Khuyến nghị tự động hay các thuật toán khuyến nghị đặc biệt là học máy, học sâu (trí tuệ nhân tạo) mới là phương pháp đang làm chủ cuộc chơi. Đây là những phương pháp có khả năng học được hồ sơ người dùng một cách tự động, sau đó sinh ra những khuyến nghị cho từng mục tiêu riêng lẻ với tỉ lệ thành công rất cao. Có rất nhiều kiến trúc khuyến nghị tự động, nhưng kiến trúc được đánh gía cao và đang được nhiều hãng công nghệ lớn sử dụng đó là 2-stage recommendation system. Hệ thống đó có thể được hình dung như sau:

Hệ thống này dựa chủ yếu vào dữ liệu hành vi của người dùng trên các nền tảng như web, app,.. và dữ liệu sản phẩm (product data). Lí do hệ thống này được gọi là 2-stage là bởi vì để sinh ra được tập sản phẩm khuyến nghị từ lịch sử hành vi của khách hàng thì phải mất 2 công đoạn chính:
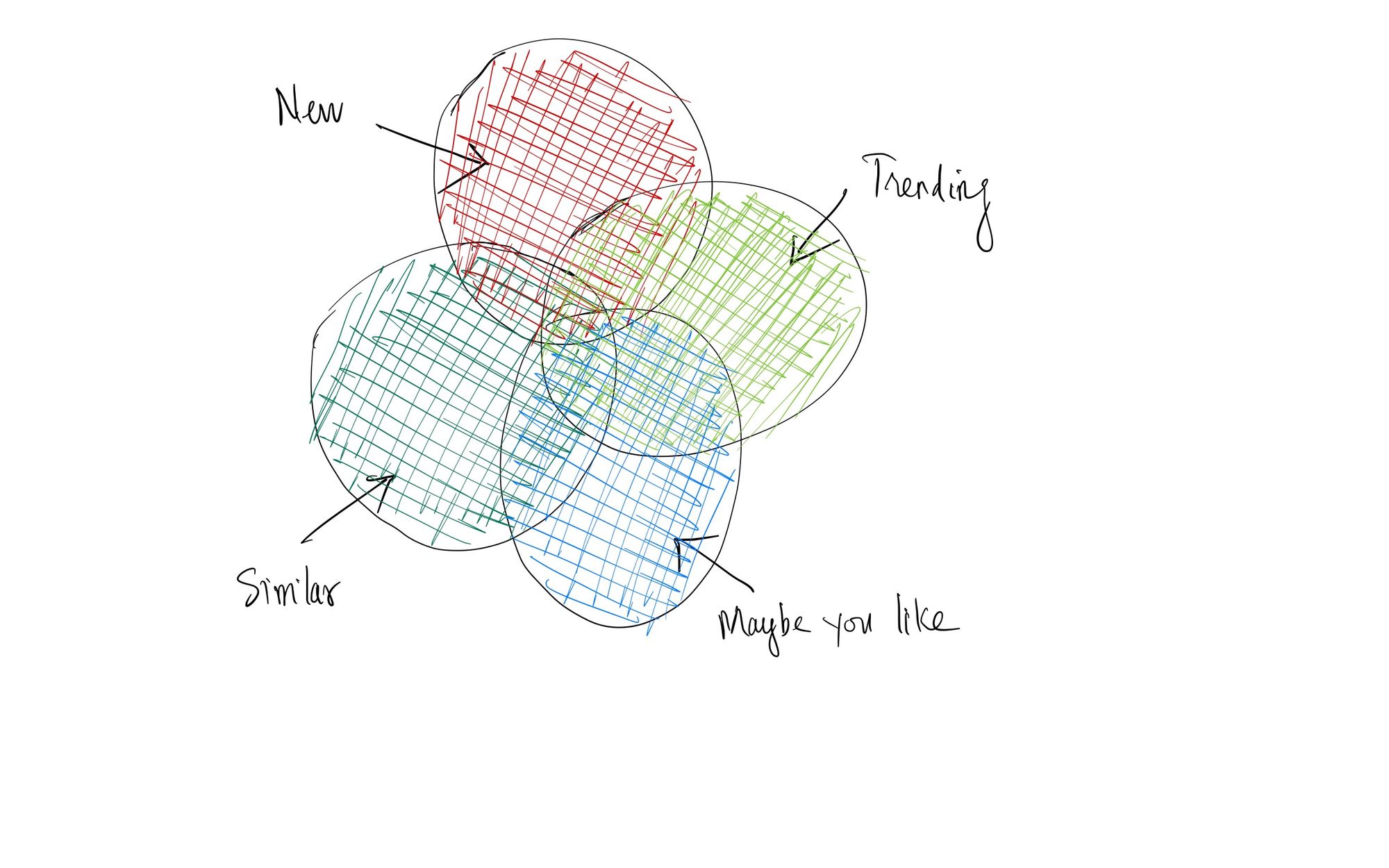
- Candidate Generator (f): Đây là công đoạn đầu tiên và có phần khó khăn vì từ danh sách những hành động mà người dùng đã thực hiện. Thuật toán phải thực hiện truy vấn ra những danh sách sản phẩm phù hợp với người dùng đó. Như ở ví dụ trên, từ danh sách behaviours {(click, x); (view, y); (purchase; z)} thì thuật toán phải sinh ra 3 danh sách sản phẩm khác nhau. Thứ nhất là similar candidates, đây là danh sách những sản phẩm giống với sản phẩm đã mà người dùng đã tương tác. Thứ hai, new candidates, đây cũng là danh sách những sản phẩm liên quan đến những sản phẩm mà người dùng đã tương tác. Nhưng phải kèm theo một tiêu chí đó là các sản phẩm này phải mới. Thứ ba là trending candidates, đây tiếp tục là những sản phẩm giống với những sản phẩm mà người dùng đã tương tác. Tuy nhiên lần này tiêu chí là nó phải nằm trong danh sách những sản phẩm hot, đang bán chạy. Tương tự như vậy, tuỳ thuộc vào mục tiêu của đội ngũ phát triển mà chúng ta có thể có nhiều loại candidates hơn với nhiều tiêu chí khác nhau. Tất cả chúng được bỏ vào một nơi gọi là candidate pool. Đây là bước chuẩn bị để cho bước ranking phía sau được dễ dàng và nhanh chóng hơn, cũng như đảm bảo những tiêu chí đề ra. Hãy tưởng tượng thay vì phải ranking toàn bộ 1 triệu sản phẩm trong cơ sở dữ liệu thì bây giờ số lượng sản phẩm đã được thu nhỏ lại nhờ candidate generator với chỉ khoảng 1000 sản phẩm. Đây là một cải thiện rất đáng kể về mặt hiệu suất của hệ thống.
- Ranking (g): Sau khi đã có được candidate pool cho người dùng cần truy vấn. Chúng ta phải thực hiện ranking lại toàn bộ sản phẩm trong pool này để làm sao khi sắp sếp danh sách sản phẩm khuyến nghị. Sản phẩm có tỉ lệ khuyến nghị thành công cao nhất phải có điểm ranking cao nhất.
Vậy f và g được thực hiện như thế nào? Về cơ bản, trong bài viết này chúng ta sẽ không đi quá sâu vào công nghệ và thuật toán. Nhưng chúng ta có thể xem hình sau mô tả một số thuật toán kinh điển của candidate generator và ranking.

Đối với f, có 2 nhóm thuật toán phổ biến được sử dụng đó là collaborative filtering (lọc cộng tác) và content filtering (lọc nội dung). Trong khi collaborative filtering chủ yếu dựa trên dữ liệu tương tác của người dùng với sản phẩm (user-item) thì nhóm thuật toán content filtering lại dựa vào dữ liệu meta-data của chính sản phẩm để khuyến nghị (item-item). Trên thực tế, thường các hệ thống khuyến nghị hoàn chỉnh đều kết hợp tất cả những phương pháp này lại với nhau. Từ đó ta có tên gọi hybrid filtering. Còn với g, hiện nay có vẻ các thuật toán ranking and filter đơn giản đang dần bị thay thế bởi phương pháp learn-to-rank dựa trên nền tảng học máy và học sâu. Ngoài ra, phương pháp học sâu từ đầu đến cuối (end-to-end neural network) cũng đang cho thấy tiềm năng không hề nhỏ.
Thí nghiệm liên tục
Sau khi đã phát triển thành công thuật toán khuyến nghị thì chúng ta phải có khả năng đánh giá hiệu quả của nó. Hoặc giữa rất nhiều giải pháp khuyến nghị được đưa ra thì giải pháp nào là tốt nhất? Khi đó, khái niệm thí nghiệm liên tục (continous experiment system) ra đời. Về cơ bản, hệ thống thí nghiệm và cải tiến liên tục thường được hiện thực trên ý tưởng A/B testing.
Giả sử, tại màn hình product view của ứng dụng có nút "mua hàng". Nhưng chúng ta băn khoăn không biết nên để nút này có màu xanh hay màu đỏ thì khách hàng sẽ thích hơn. Khi đó, ta có thể thực hiện một thí nghiệm như sau. Đầu tiên đó là hiện thực cả 2 phiên bản ứng dụng với nút "mua hàng" màu xanh và màu đỏ. Kế tiếp, ta thực hiện điều hướng %50\%% lượng truy cập vào ứng dụng vào version A, %50\%% lượng truy cập vào version B. Khi đó, chúng ta sẽ có %50\%% người dùng nhìn thấy nút "mua hàng" màu xanh và %50\%% người dùng nhìn thấy nút "mua hàng" màu đỏ.
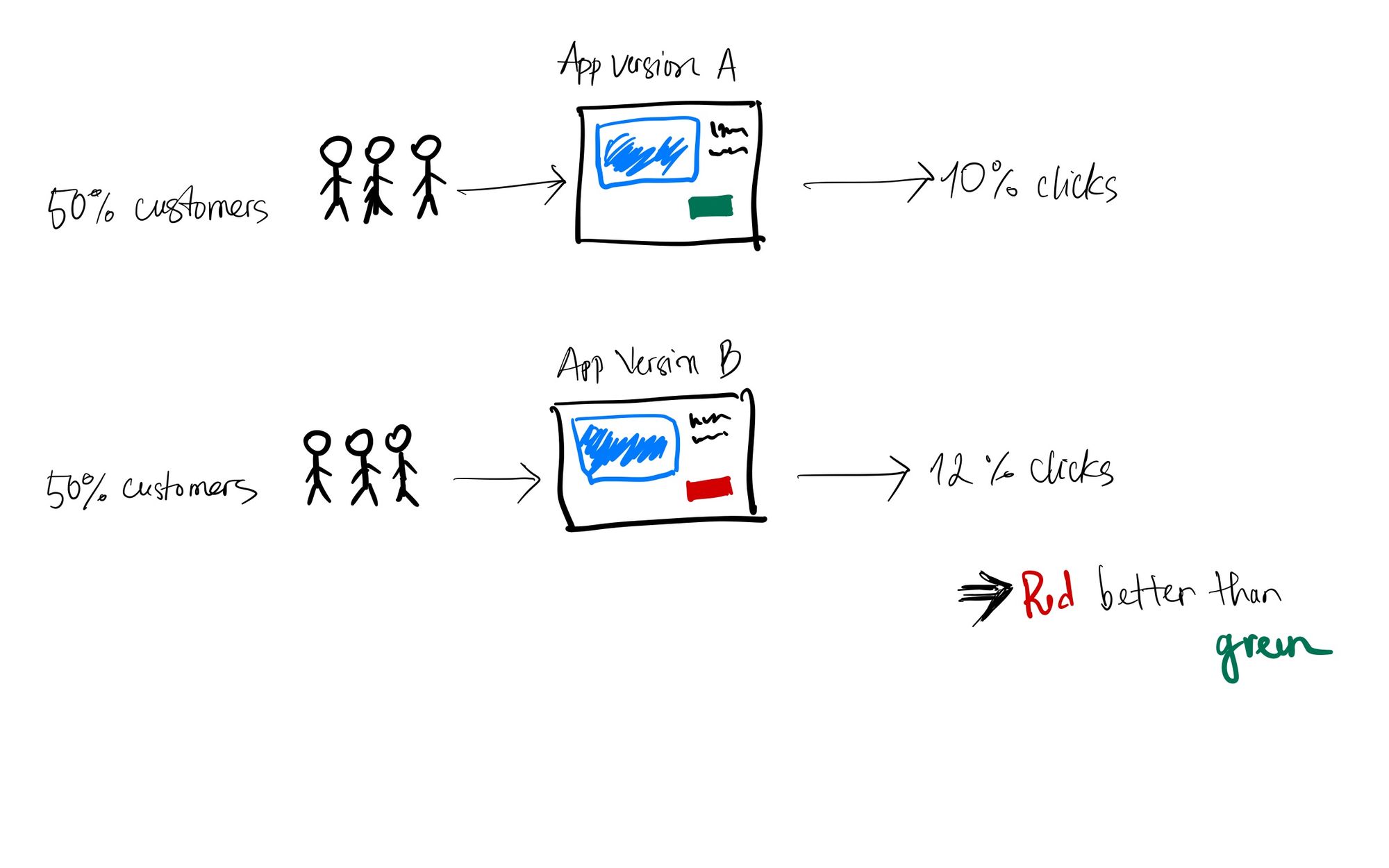
Sau khi đã điều hướng thành công, hệ thống sẽ thực hiện đo đạt các thông số cần thiết như tỉ lệ chuyển đổi (conversion rate), thời gian xem trang (page view time) để đưa ra kết luận là version nào tốt hơn. Tương tự như vậy chúng ta có thể thiết lập những thí nghiệm A/B/n Testing với số lượng phiên bản nhiều hơn, như test cùng lúc 5 phiên bản chẳng hạn.
Một trong những vấn đề lớn của hệ thống thí nghiệm liên tục đó chính là thu thập những feedback (phản hồi) của khách hàng về ứng dụng. Dữ liệu đủ tốt sẽ giúp cho chúng ta đưa ra những kết luận chính xác.
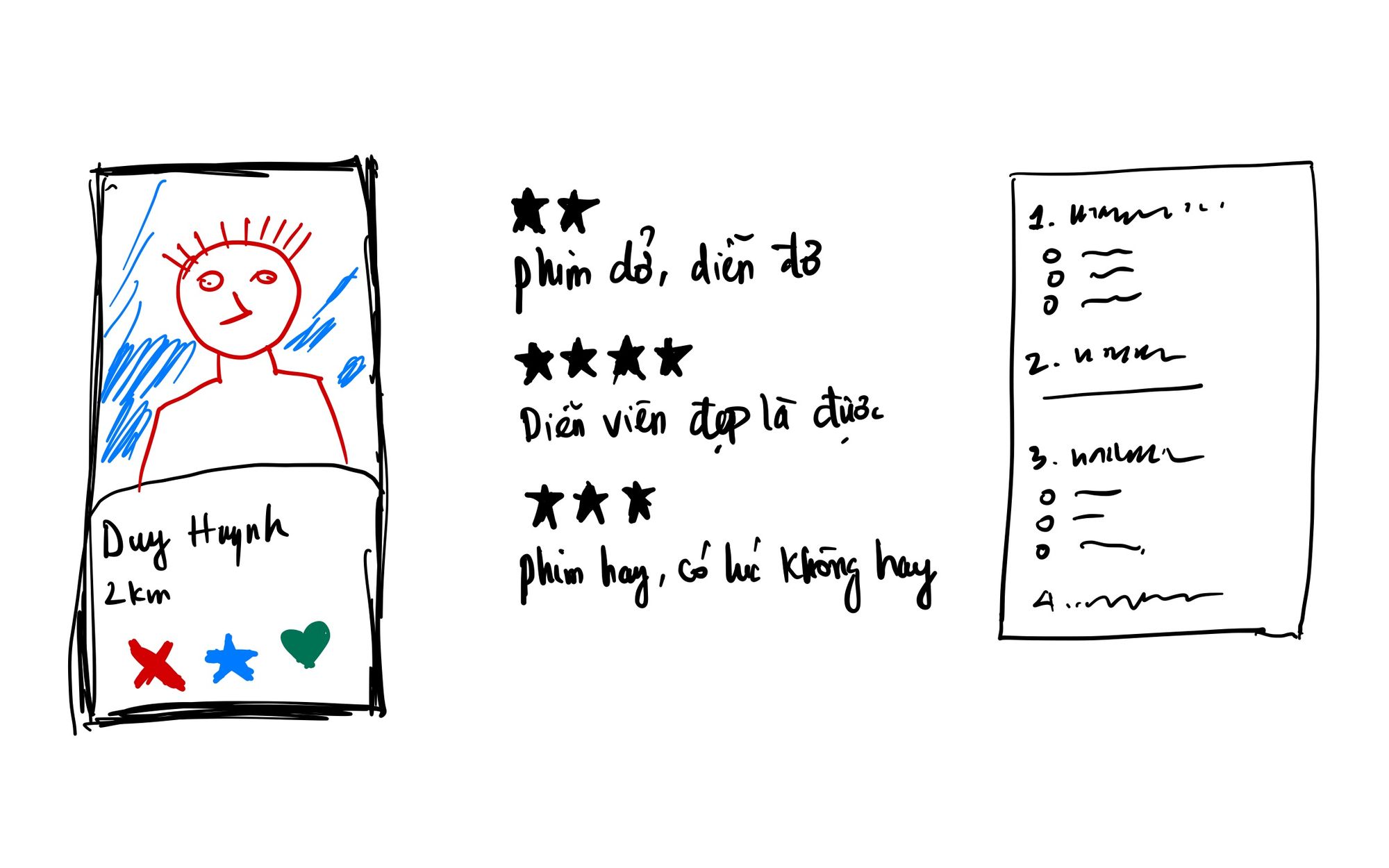
Ta có một số phương pháp thu thập phản hồi phổ biến như hình trên. Ví dụ, thuật toán matching (ghép đôi) đằng sau các ứng dụng hẹn hò có thể xem là một loại thuật toán khuyến nghị. Những ứng dụng này có thể nhận lại phản hồi của người dùng như những lượt bấm like, dislike, thả tim. Còn với các ứng dụng xem phim, thương mại điện tử thì sẽ có phần bình luận và đánh giá. Hoặc nếu muốn dữ liệu chính xác hơn ta có thể bỏ công thực hiện những khảo sát phía khách hàng. Tất cả những dữ liệu này phải được tính toán và phân tích một cách kỹ càng bởi đội ngũ phát triển. Bởi vì phản hồi của người dùng là những thông tin rất có giá trị, không nên bỏ qua. Có thể nói đây chính là xương sống của bất kỳ sản phẩm công nghệ nào muốn lấy khách hàng làm trung tâm (customer-centric).
Thách thức
Để phát triển một hệ thống khuyến nghị hoàn chỉnh tốn rất nhiều công sức. Tuy nhiên, đó vẫn chưa phải là thách thức lớn nhất. Thách thức lớn nhất của bất kỳ giải pháp công nghệ nào không phải nằm ở giai đoạn phát triển ban đầu. Mà là quá trình cải tiến và thay đổi. Với tốc độ tăng trưởng rất nhanh như các start-up công nghệ, sự thay đổi của các mục tiêu kinh doanh (business goal) là cực kỳ nhanh. Chúng ta vẫn thường nghĩ một hệ thống khuyến nghị tốt phải giúp tăng tỉ lệ chốt đơn của khách hàng ngay lập tức. Tuy vậy, thực tế mục tiêu kinh doanh của các start-up không phải lúc nào cũng là doanh thu. Đôi khi chúng ta phải giải quyết vấn đề long-tail (khi %10\%% sản phẩm chiếm %90\%% page view của toàn bộ nền tảng), thì lúc đó mục tiêu của hệ thống khuyến nghị là giúp cải thiện page view của %90\%% sản phẩm còn lại. Hoặc sau khi phân tích ta nhận thấy %95\%% các sản phẩm mới không có page view trong 30 ngày đầu tiên lên sàn, thì lúc đó ta lại cần một chiến lược để hỗ trợ các sản phẩm này có page view. Do đó, một hệ thống khuyến nghị tốt phải đủ khả năng đáp ứng một cách linh hoạt và nhanh chóng các mục tiêu khác nhau cho từng giai đoạn khác nhau của mô hình kinh doanh. Đó là lí do vì sao ta phải có nhiều loại candidate trong candidate pool.
Một thách thức khác lớn không nhỏ đó là khả năng phản ứng real-time với hành động của người dùng để đưa ra những gợi ý phù hợp. Để xây dựng những hệ thống như vậy thì ngoài thuật toán, nền tảng tính toán hiệu năng cao cũng cực kỳ quan trọng. Ngoài ra, khả năng nhận biết những feedback không tường minh của khách hàng cũng thử thách không kém. Ví dụ, khi hệ thống hiện cho khách hàng một danh sách sản phẩm gợi ý, mà cả ngày khách hàng đó không thực hiện bất kỳ một lượt xem page view nào thì có nghĩa là danh sách đó chưa tốt và cần được cập nhật. Tuy khách hàng không hề thực hiện hành động nào, những chúng ta phải ngầm hiểu là danh sách chúng ta chưa ra chưa đủ hấp dẫn hoặc bị trùng lập gì đó.
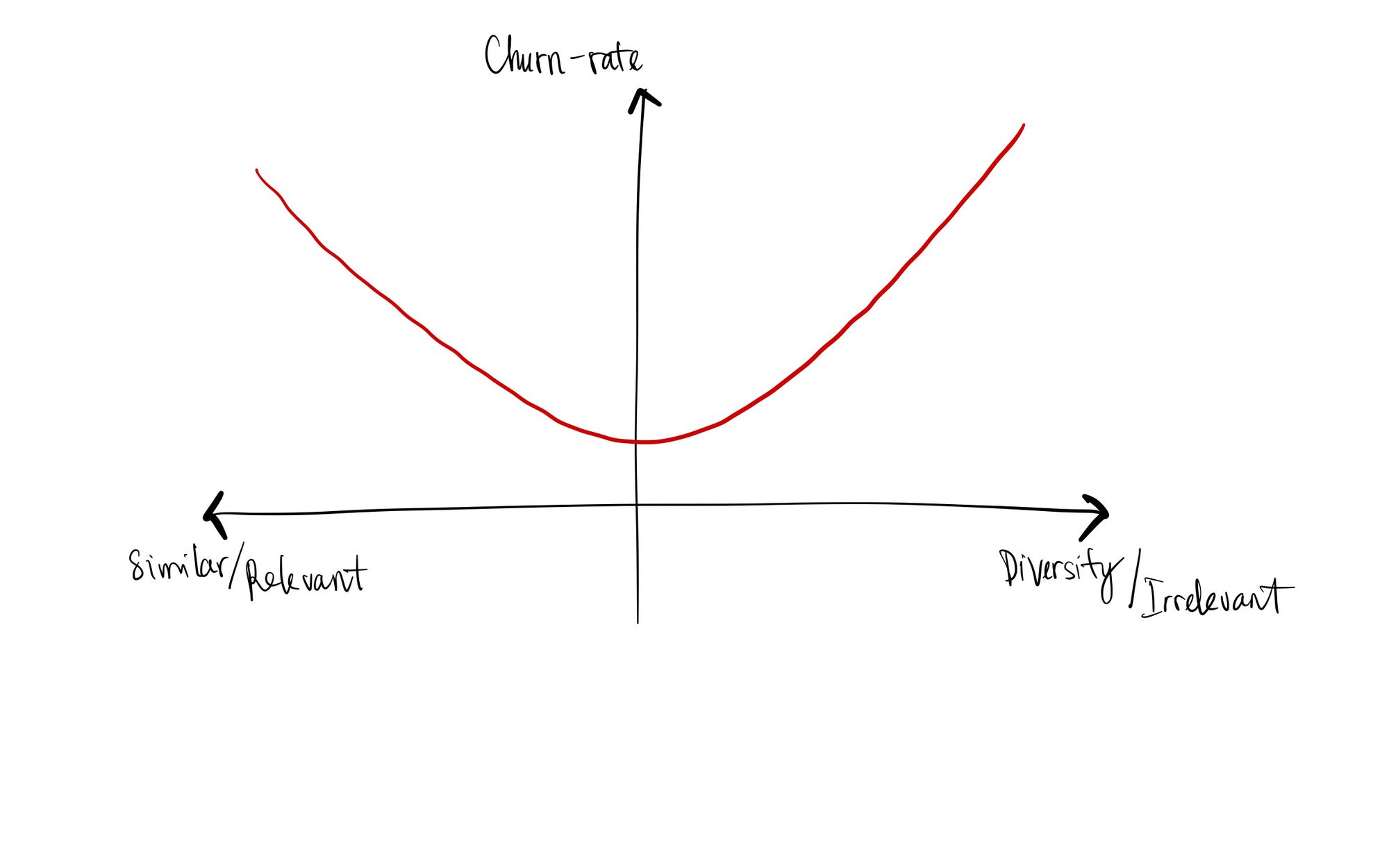
Một sai lầm điển hình khác khi xây dựng danh sách gợi ý chính là việc chọn những sản phẩm quá giống hoặc quá khác với các sản phẩm mà người dùng đã từng tương tác. Điều đó làm tăng sự chán nản của người dùng và khiến họ dễ dàng từ bỏ nền tảng. Cho nên chúng ta cần phải tìm ra điểm cân bằng của hai khía cạnh đó.
Kết
Trên đây là một cái nhìn tổng quan về hệ thống khuyến nghị. Công nghệ sẽ còn tiếp tục cải tiến và phát triển. Nhưng không thể phủ nhận các hệ thống khuyến nghị hiện nay đang hoạt động quá tốt và trở thành hạt nhân chính cho rất nhiều sảm phẩm đình đám. Việc nắm vững và làm chủ công nghệ này sẽ giúp các doanh nghiệp kinh doanh nội dung số có chỗ đứng trong thị trường đầy cạnh tranh hiện nay. Tuy vậy, việc phát triển một hệ thống hoàn chỉnh bao gồm cả tracking system, algorithm, experimentation system là không hề đơn giản. Các doanh nghiệp cần có chiến lược phù hợp với tình hình thực tế về nguồn lực và mục tiêu kinh doanh của mình để đưa ra giải pháp tốt nhất. Sử dụng dịch vụ sẵn có của các hãng công nghệ lớn cũng là một giải pháp: Amazon Personalize, Google Recommendations AI, Azure ML,..
Tham khảo thêm
- TikTok considers monetization and creator retention in judging recommendation algorithm.
- Using A/B testing to measure the efficacy of recommendations generated by Amazon Personalize.
- Recommending items to more than a billion people.
- How Netflix Utilizes Data Science.
- On YouTube’s recommendation system.
- Top Highlighted Recommendation System Ideas from Alibaba.
- How To Deal With Cross Device Sessions in Realtime at Scale.
- TIKI scales data platform visualization với Apache Druid như thế nào.