Build your own Redis (1/5) - Redis Serialization Protocol and Concurrency Model
Redis represents a masterclass in systems design, particularly in how it balances performance with architectural elegance. Through implementing a Redis-compatible server via the CodeCrafters challenge, we'll deconstruct two fundamental architectural decisions that shape Redis's behavior: its wire protocol (RESP) and its event-driven concurrency model.
If you're interested in trying the Build Your Own Redis challenge yourself, you can use my referral link to get a free week on CodeCrafters. It's an excellent platform for learning system design through hands-on projects, and I highly recommend giving it a try!

Why Protocol Design Matters
Before diving into Redis's wire protocol, let's understand why protocol design is crucial for distributed systems. When building networked applications, we need a reliable way for different parts of our system to communicate. This communication protocol needs to handle several critical requirements:
- Efficient encoding and decoding of data
- Graceful handling of partial messages and network failures
- Easy implementation across different programming languages
- Human readability for debugging purposes
Redis addresses these challenges through RESP (Redis Serialization Protocol), a deliberately simple yet powerful wire protocol that strikes an elegant balance between these requirements.
Understanding RESP
Think of RESP as a shared language that Redis clients and servers use to communicate. Just as human languages have grammar rules and sentence structures, RESP has its own set of conventions that make communication reliable and efficient.
RESP uses different prefixes to indicate different data types, similar to how we use punctuation marks to convey meaning in written text. Each message in RESP ends with \r\n (CRLF), providing clear message boundaries – much like how we use periods to separate sentences.
Here's how RESP represents different data types:
- Simple Strings start with '+' (e.g.,
+OK\r\n) - Errors start with '-' (e.g.,
-Error message\r\n) - Integers start with ':' (e.g.,
:1000\r\n) - Bulk Strings start with '$' followed by length (e.g.,
$5\r\nhello\r\n) - Arrays start with '*' followed by count (e.g.,
*2\r\n$4\r\nECHO\r\n$5\r\nhello\r\n)
For the full list of RESP data types, please refer to this documentation.
Let's implement these concepts in code. First, I create a class hierarchy to represent RESP data types:
This class hierarchy provides a strong foundation for handling RESP messages. Each class maintains both its logical value and metadata about its wire format representation, enabling efficient parsing and serialization.
The real challenge lies in parsing these RESP messages correctly, especially with bulkstring and array which require parsing the length before reading the actual values. Here's how I implement the core parsing logic:
Redis's Concurrency Model
Redis's approach to concurrency represents a deliberate departure from traditional multi-threaded database architectures. Instead of thread-per-connection or thread pool models, Redis employs event-driven I/O multiplexing through a single-threaded event loop.
Imagine a skilled waiter serving multiple tables in a restaurant. Rather than dedicating one waiter per table (which would be like creating one thread per connection), a single experienced waiter can efficiently serve many tables by constantly moving between them, taking orders, delivering food, and processing payments. The waiter doesn't stand still waiting for each customer to finish their meal before moving to the next table.
Here's how we implement this pattern using Python's asyncio:
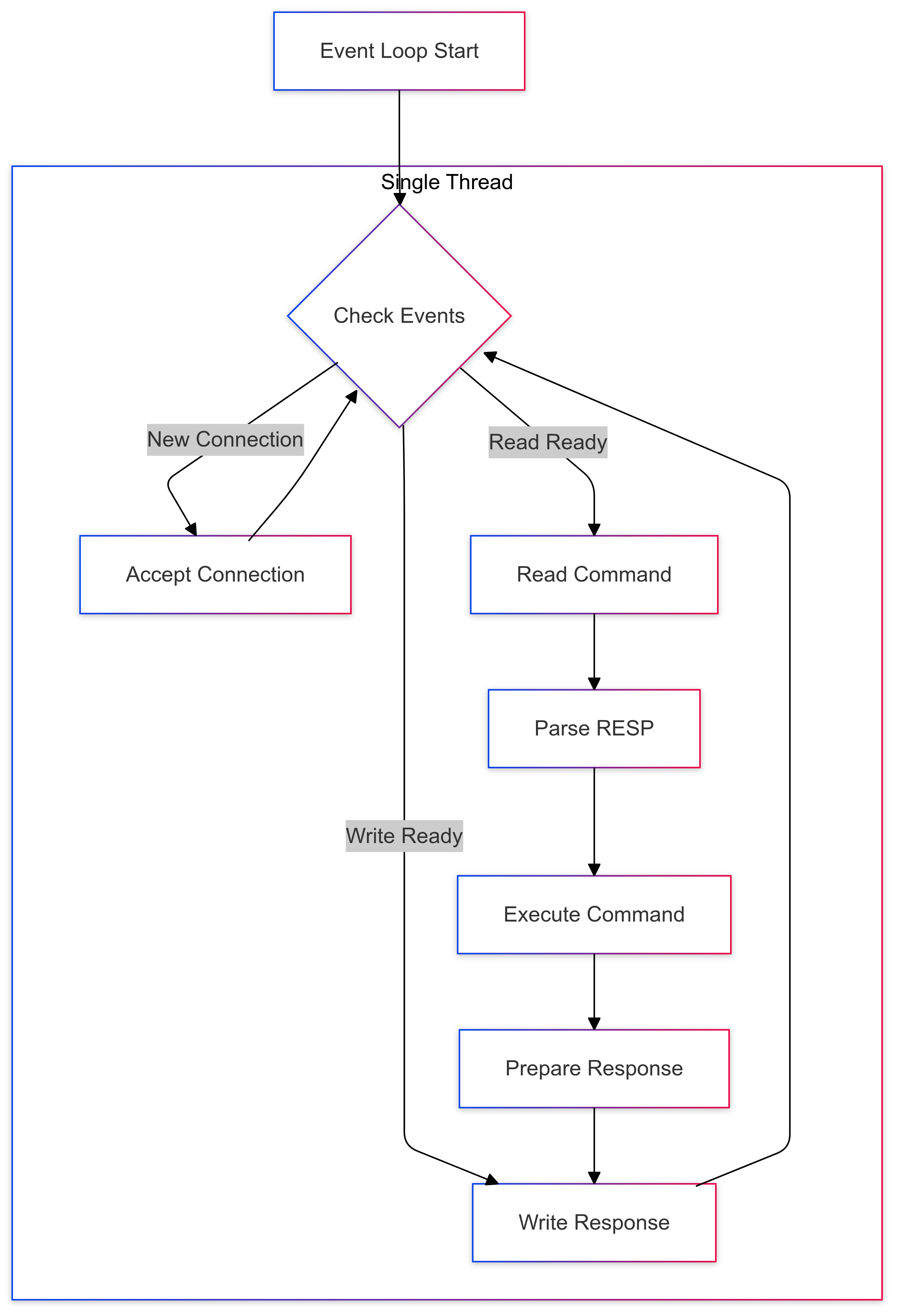
Command Processing Flow
The command processing pipeline brings everything together in a seamless flow:
- A client sends a RESP-formatted command
- The event loop receives the bytes
- The RESP parser converts them into structured commands
- The command handler executes the operation
- The response is serialized back to RESP format
- The event loop sends the response back to the client
Here's how I implement command handling:
How They Scale?
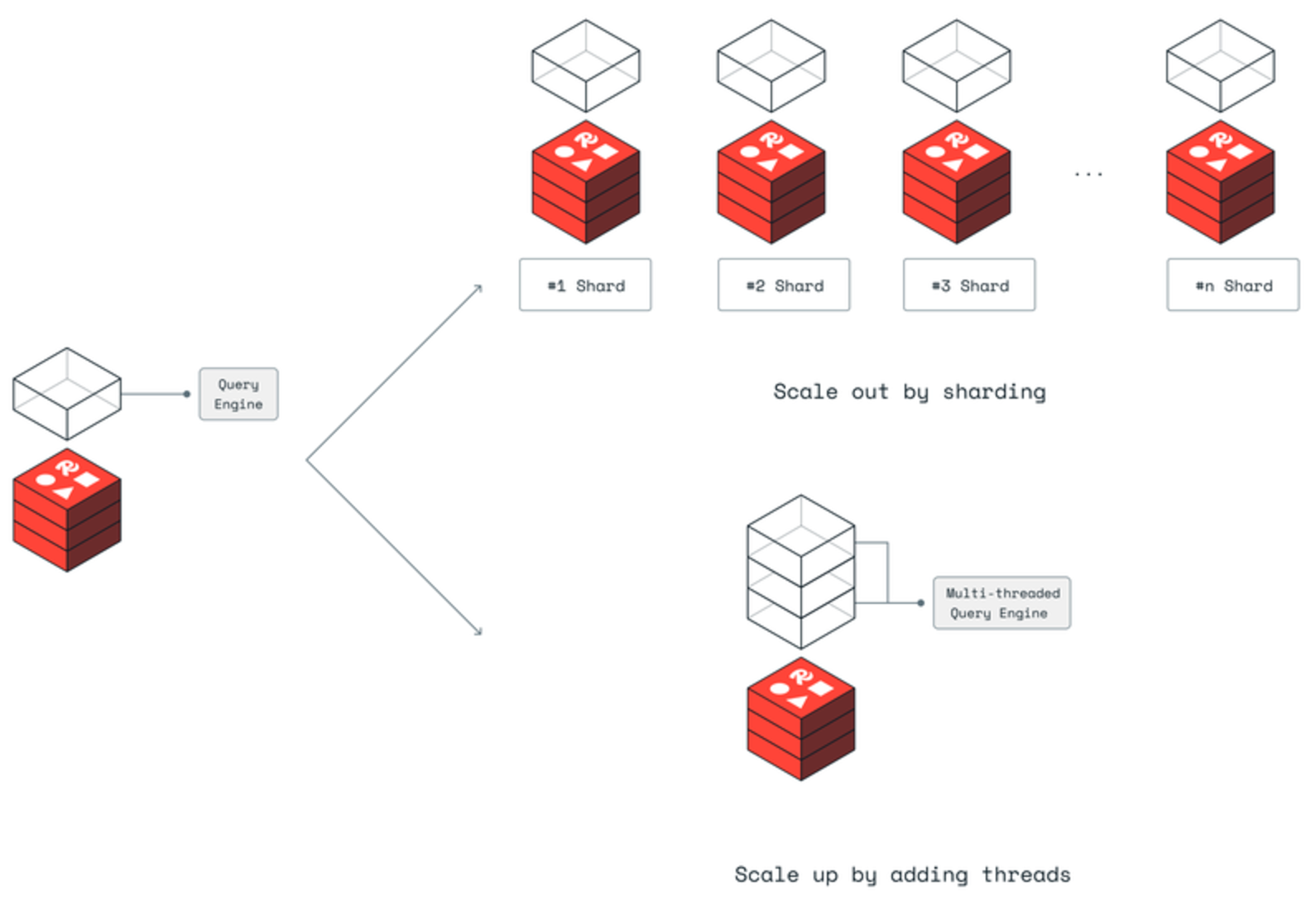
But how does Redis scale without multiple threads? The answer lies in its clever use of process-level parallelism. Rather than splitting work within a single process, Redis runs multiple independent processes, each handling up to 25GB of data. This limit isn't arbitrary – it's carefully chosen to optimize memory management operations like copy-on-write and ensure smooth data migrations.
This architectural choice creates a cascade of performance benefits. When you need more capacity, you can scale both "up" by adding more Redis processes to a single machine and "out" by adding more machines to your cluster. For more details, please refer to the official post from Redis team.
However, this single-threaded philosophy has been a subject of intense debate in the database community. Modern alternatives like KeyDB and Dragonfly have diverged from this approach, embracing multi-threading to leverage modern multi-core processors. However, responding to emerging AI ecosystem requirements and specialized workloads like vector queries, Redis introduced a multi-threaded query engine in June 2024. This addition significantly reduces latency when handling multiple complex queries concurrently, demonstrating Redis's evolution to meet modern computational demands while maintaining its core architectural principles.
Lessons
Redis's architecture offers profound insights into distributed systems design:
- Protocol Design: RESP demonstrates how grammatical simplicity enables robust implementations
- Concurrency Models: Thread-per-connection isn't always optimal; event loops can provide superior efficiency,
In the next part, we'll explore how Redis builds on these foundations to implement persistence through RDB and AOF mechanisms, showing how even durability features can be added without compromising Redis's core performance characteristics.
The complete implementation is available in this GitHub repository, providing a practical foundation for exploring these concepts further.