Bloom Filter: Cấu trúc dữ liệu dựa trên xác suất

Bloom filter là một cấu trúc dữ liệu dựa trên xác suất được giới thiệu lần đầu bởi Burton Howard Bloom vào năm 1970. Đây là một cấu trúc dữ liệu đơn giản nhưng cực kỳ hiệu quả và được dùng trong rất nhiều ứng dụng khác nhau, đặc biệt là các hệ thống lớn. Bloom filter giúp trả lời hiệu quả câu hỏi rất quan trọng trong các hệ thống tìm kiếm đó là kiểm tra một bản ghi có tồn tại trong cơ sở dữ liệu hay không?
Cấu trúc dữ liệu này gồm 2 thành phần chính là %k% hash function và một mảng nhị phân %m% phần tử. Đặc biệt các hash function này phải là các hàm ánh xạ dữ liệu đầu vào thành các số trong đoạn %[0..m-1]%.
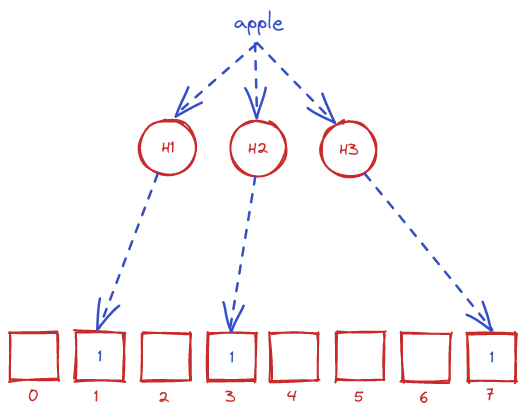
Ta cùng xét ví dụ về bloom filter với %k=3% và %m=8% như bên dưới. Giả sử ta insert một bản ghi dữ liệu với key "apple" vào cơ sở dữ liệu, thì trước tiên "apple" sẽ được đi qua 3 hash function H1, H2, H3. Mỗi hash function sẽ cho ra kết quả là một số trong đoạn %[0..m-1]%, ta thực hiện bật bit ở vị trí tương ứng trong mảng nhị phân thành 1. Như trong hình, sau khi đi qua 3 hàm hash, ta được chuỗi vị trí được bật bit đó là [1, 3, 7].
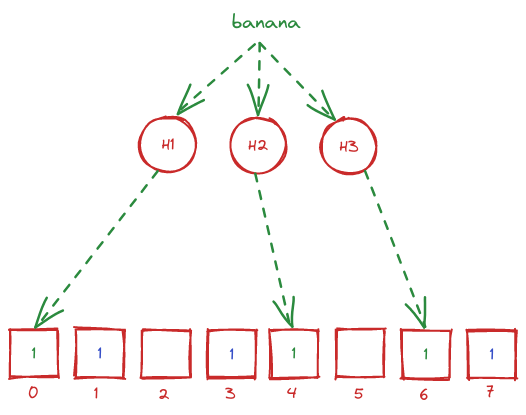
Làm tương tự với key "banana", khi đó sẽ được mảng nhị phân như sau:
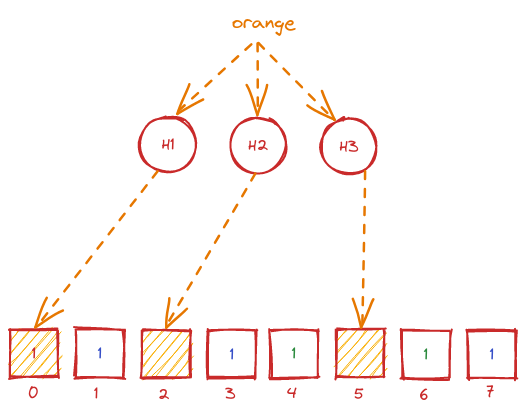
Sau khi đã insert 2 key "apple" và "banana" vào cơ sở dữ liệu, bây giờ chúng ta sẽ có một truy vấn mới đó là xác định xem key "orange" có tồn tại trong cơ sở dữ liệu hay không. Cũng tương tự như truy vấn insert, "orange" cũng được cho qua 3 hàm hash H1, H2, H3. Nhưng lần này thay vì bật bit thì chúng ta sẽ kiểm tra xem bit tại vị trí của giá trị hàm hash đã bật hay chưa. Nếu có bất kỳ một bit nào bằng 0 tức là chắc chắn "orange" không tồn tại trong cơ sở dữ liệu. Ngược lại nếu tất cả các bit bằng 1 thì ta có thể kết luận rằng "orange có khả năng nằm trong cơ sở dữ liệu". Bởi vì một chuỗi các bit 1 có thể là kết quả hàm hash của rất nhiều key khác nhau, do đó ta không thể chắc chắn trong trường hợp này. Đó cũng là lí do bloom filter được gọi là cấu trúc dữ liệu dựa trên xác suất.
Từ ví dụ trên, ta nhìn thấy rằng kết quả của truy vấn "phần tử x có tồn tại trong cơ sở dữ liệu hay không?" luôn cho ra kết quả chính xác cho câu trả lời "không", còn nếu câu trả lời là "có" thì ta phải kiểm tra thêm đây có phải là false postive hay không. Tuy nhiên, việc đưa ra câu trả lời "không" cũng đã giúp cho các hệ thống tìm kiếm giảm tải đi được rất nhiều truy vấn không cần thiết vào database. Ngoài ra, khi thiết kế bloom filter thì số lượng hàm hash và kích thước mảng nhị phân là thông số quan trọng biểu thị sự đánh đổi giữa accuraccy và computational efficiency. Số lượng hàm hash và kích thước mảng nhị phân càng lớn thì độ chính xác của filter càng cao, giúp lọc được nhiều negative sample hơn, nhưng lại tốn nhiều tài nguyên hơn về cả tính toán lẫn bộ nhớ. Ngược lại, nếu hai thông số trên nhỏ thì thuật toán chạy càng nhanh, nhưng lại ít chính xác hơn.
Có thể thấy bloom filter là một cấu trúc dữ liệu rất đơn giản, nhưng lại được dùng rất nhiều trong thực tế:
- Các cơ sở dữ liệu lớn như Google Bigtable, Cassandra, HBase sử dụng bloom filter để kiểm tra dữ liệu có tồn tại hay không trước khi truy vấn vào database engine.
- Google Chrome dùng bloom filter để chặn các URL độc hại, còn Google Bot thì dùng để deduplicate URL trong quá trình crawling.
- Các hệ thống caching, tìm kiếm hay virus scanning cũng dùng bloom filter rất nhiều để tối ưu hệ thống của họ.