An example of millions-scale application

Nhờ sự phát triển mạnh mẽ của các công cụ và nền tảng lập trình, việc phát triển ứng dụng không còn là điều quá khó khăn. Thậm chí, lập trình viên có thể thoải mái lựa chọn bộ công cụ mà mình yêu thích để hiện thực ứng dụng. Tuy nhiên, để thiết kế một ứng dụng có thể phục vụ hàng triệu người dùng không phải là điều đơn giản. Hơn thế nữa, các mô hình kinh doanh lấy ứng dụng làm trung tâm đã trở nên rất phổ biến (ví dụ như các trang thương mại điện tử, mạng xã hội, nền tảng xem phim, nghe nhạc trực tuyến,..). Do đó, các mô hình này vừa đòi hỏi ứng dụng phải có khả năng đáp ứng lượng lớn người dùng và có khả năng thay đổi và đáp ứng nhanh chóng nhu cầu kinh doanh. Việc thiết kế một ứng dụng như vậy không phải là điều đơn giản. Trong bài viết này, chúng ta sẽ tìm hiểu một ví dụ đơn giản về cách thiết kế một ứng dụng đáp ứng được cả hai tiêu chí trên.
Single server web application
Đầu tiên, trước khi nghĩ đến cái gì đó quá to lớn, chúng ta hãy hình dung về việc xây dựng ứng dụng cơ bản với một server duy nhất như sau.
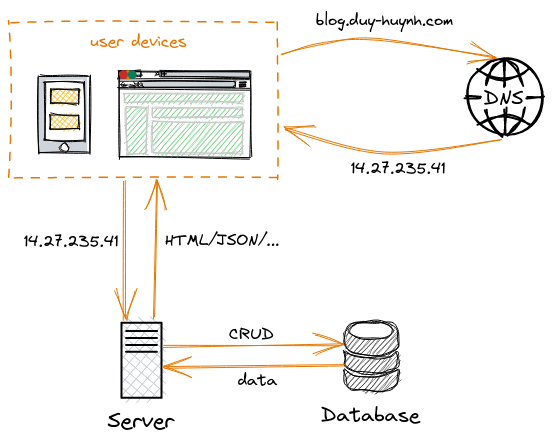
Luồng dữ liệu của ứng dụng này rất đơn giản:
- User device bao gồm các thiết bị đầu cuối của người dùng để tương tác với ứng dụng: máy tính, smartphone, tablet,.. User device gửi yêu cầu truy cập dữ liệu thông qua domain name đến DNS server.
- Sau khi nhận được yêu cầu, DNS server sẽ trả về cho client địa chỉ IP của server tương ứng với domain được yêu cầu. Ví dụ địa chỉ server của domain blog.duy-huynh.com là 14.27.235.41 như trên hình.
- Khi đã có được địa chỉ IP của server, user device mới dùng địa chỉ đó để thực hiện truy cập dữ liệu trực tiếp từ server của ứng dụng.
- Khi server ứng dụng nhận được yêu cầu truy cập dữ liệu, nó sẽ thực hiện một số bước như kiểm tra yêu cầu, xác thực danh tính người dùng trước khi gửi yêu cầu đến cơ sở dữ liệu (database) chính của ứng dụng. Nếu đã lấy được data rồi thì server sẽ phản hồi về phía user device thông qua các chuẩn giao tiếp trên tầng application như HTML, JSON, XML, YAML...
- Bước cuối cùng là từ dữ liệu lấy được, user device sẽ thực hiện giãi mã và hiển thị lên thiết bị đầu cuối kết quả mà người dùng mong muốn.
Đây là quy trình khá phổ biến cho các ứng dụng quy mô nhỏ. Mô hình này có thể đáp ứng được vài chục, và trăm, đến vài nghìn user cùng một lúc tùy theo sức mạnh của server.
Vertical scaling vs horizontal scaling
Với mô hình single server như trên, ta có thể thấy việc mở rộng về mặt ý tưởng là tương đối dễ. Nếu muốn mở rộng ứng dụng để có khả năng chịu tải tốt hơn thì ta chỉ cần một server mạnh hơn với nhiều RAM hơn, nhiều CPU hơn, nhiều ổ cứng hơn,... Chiến lược này được gọi là vertical scaling hay "scale up". Trên thực tế, nếu chỉ thực hiện chiến lược vertical scaling thôi thì vẫn không đủ. Dù sao khối lượng phần cứng được thêm vào server cũng có hạn. Đặc biệt, một hệ thống đơn nhất như vậy thì rất khó để duy trì tính khả dụng (availability) trong thời gian dài. Cho dù một server duy nhất đó có thể phục vụ được hàng triệu người dùng thì nếu như nó gặp trục trặc hay vấn đề gì thì sao, khi đó chúng ta sẽ không có giải pháp để thay thế. Một chiến lược khác giúp giải quyết tốt tình huống này đó là horizontal scaling hay "scale out". Thay vì thêm sức mạnh cho từng server thì horizontal scaling mở rộng bằng cách replicate server thành nhiều node. Khi đó, nếu một hoặc nhiều node gặp trục trặc thì lưu lượng truy cập (traffic) sẽ được chuyển qua các node còn hoạt động tốt. Điều này giúp nâng cao tính khả dụng của hệ thống trong nhiều tình huống.
Tron ứng dụng thực tiễn, hai chiến lược scaling này luôn được sử dụng cùng lúc tùy theo yêu cầu của hệ thống. Đối với kiến trúc scale out, ta cần thiết phải sử dụng thêm load balancer để điều hướng truy cập từ phía client. Load balancer có nhiệm vụ điều tiết tải lượng cho các node của server. Ví dụ ta có 3 node server, thì load balancer sẽ điều hướng truy cập để cả 3 có lượng truy cập đều nhau. Hoặc khi 1 trong 3 node gặp trục trặc thì load balancer sẽ điều hướng truy cập vào 2 node còn lại để duy trì tính khả dụng của hệ thống cho dù có 1 node đã không còn hoạt động. Chúng ta hoàn toàn có thể áp dụng kỹ thuật scale out tương tự cho database, khi đó ta sẽ được mô hình như sau:
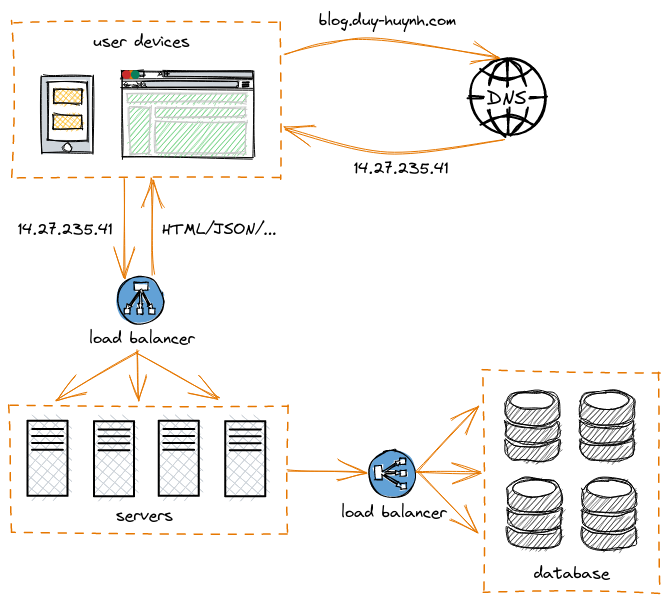
Sau khi đã thực hiện hai chiến lược scale-up và scale-out, chúng ta có thể thấy hệ thống đã linh hoạt hơn nhiều. Hệ thống đã có khả năng ứng phó với các trục trặc kỹ thuật một cách nhanh chóng. Các trường hợp cần mở rộng trong thời gian ngắn ví dụ như peak event (thời điểm có lương truy cập cao) cũng được giải quyết một cách thuận lợi. Trường hợp điển hình hay gặp ở các dịch vụ trực tuyến đó là vào những chương trình khuyến mãi, kick-off sale campaign thì sẽ có lương truy cập tăng đột biến, sau đó lưu lượng lại giảm dần về như cũ. Việc xây dựng hệ thống phần cứng on-premise đủ mạnh chỉ để đáp ứng những thời điểm này là rất tốn kém và không hợp lí. Tuy nhiên với chiến lược scale-out, ta hoàn toàn có thể replicate thêm nhiều node server + database vào những thời điểm peak event, sau khi kết thúc sự kiện thì shutdown chúng. Đây là một chiến lược hợp lí, và đặc biệt các hệ thống cloud vendor lớn đều cung cấp các dịch vụ scale-out serverless kiểu này. Các hệ thống linh hoạt như thế này thường sử dụng các công nghệ dựa trên nền tảng hóa hóa container như docker, k8s, swarm,...
Microservices and distributed database
Một bước phát triển tiếp theo của hệ thống trên đó là microservice và distributed database. Tiếp tục ý tưởng scale-out, tuy nhiên bây giờ thay vì scale-out toàn bộ server thì chúng ta thực hiện scale-out ở một cấp độ chi tiết hơn đó là service. Một ứng dụng là một tổ hợp của rất nhiều function/method, ở mức độ cơ bản các function/method này được gộp chung với nhau vào một codebase và deploy thành một server ứng dụng duy nhất. Kiểu kiến trúc như vậy được gọi là monolithic application. Nhưng ta dễ dàng nhận ra trong một ứng dụng không phải function/method nào cũng có tần suất sử dụng như nhau. Sẽ có function/method được dùng nhiều, sẽ có function/method rất hiếm khi được sử dụng trong vòng đời của ứng dụng. Do đó việc scale-out tòan bộ server có vẻ chưa hợp lí. Thế nên ta có một hướng khác đó là thay vì viết tất cả function/method vào một codebase duy nhất. Ta có thể chia chúng ra thành những service hoặc cụm service riêng lẻ. Khi đó những service nào được dùng nhiều thì chúng ta scale thành nhiều node hơn, những service nào ít được dùng thì sử dụng ít node hơn chẳng hạn. Đây được gọi là kiến trúc microservice. Như ví dụ bên dưới, ta có thể tách một ứng dụng bán hàng trực tuyến thành 3 cụm service khác nhau: UAC (user access control) dùng để quản lý tài khoản, quyền truy cập cũng như định danh người dùng; order service dùng để quản lý luồng xem hàng, đặt hàng,....; còn payment service thì dùng để quản lý vấn đề thanh toán. Với kiến trúc monolithic thông thường việc trao đổi dữ liệu giữa các function với nhau rất dễ dàng vì chúng chạy trong cùng một tiến trình. Nhưng với micro-service thì không như vậy, cho nên ta phải có cơ chế để các service riêng lẻ có thể giao tiếp với nhau. Thông thường tùy theo yêu cầu hệ thống về latency, response type, data type và cấp độ bảo mật mà người ta có thể chọn các cơ chế giao tiếp như: REST, gRPC, AMQP,.. Tương ứng với từng kiểu giao tiếp ta có những kiểu data-encoding như JSON, XML, Protobuf,...
Ngoài kiến trúc ứng dụng, kiến trúc cơ sở dữ liệu hoàn toàn có thể được thiết kế theo hướng này. Tức là ta chia cơ sở dữ liệu thành nhiều thành phần khác nhau, mỗi thành phần lưu ở một node khác nhau của database server. Điều đó cũng giúp chúng ta dễ dàng mở rộng cơ sở dữ liệu hơn. Ví dụ những bảng dữ liệu nào thường xuyên được truy cập thì chúng ta thêm nhiều node lưu bảng đó hơn, bảng nào ít được truy cập thì chúng ta ít cần phải quan tâm hơn.
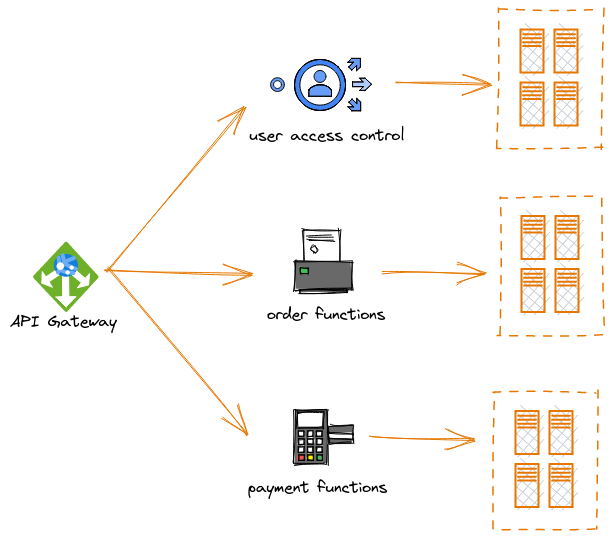
Bây giờ chúng ta có thể nhìn thấy, hệ thống đã linh hoạt hơn thêm một bật nữa khi từng nghiệp vụ được chuyên biệt hóa thành một hoặc một cụm service. Lúc này việc scale-up hay scale-down không còn là một vấn đề lớn. Đặc biệt, với kiến trúc hệ thống theo dạng plug-in plug-out như thế cũng giúp đội ngũ phát triển dễ dàng hơn trong việc phát triển các tính năng mới, cũng như bảo trì những chức năng cũ. Các đội phát triển ứng dụng có thể làm việc độc lập với nhau trên từng service riêng lẽ giúp đẩy nhanh quá trình nâng cấp ứng dụng.
Caching
Caching là khái niệm lưu trữ tạm thời giúp truy xuất nhanh dữ liệu. Đối với các hệ thống có cơ sở dữ liệu lớn, ví dụ như vừa đọc vừa ghi hàng triệu transaction mỗi ngày thì việc truy xuất dữ liệu trực tiếp từ cơ sở dữ liệu gốc (original database) là một công việc hết sức tốn tài nguyên. Hãy tưởng tượng về việc phải liên tục query trên một table SQL với hàng tỉ dòng, đó thật sự là một thảm họa. Trên thực tế không phải loại dữ liệu nào cũng có tần suất truy cập giống nhau. Do đó, ý tưởng caching là một ý hay. Ý tưởng caching rất đơn giản, thay vì phải truy cập bảng dữ liệu gốc với số lượng dòng cực khủng thì ta có thể lưu tạm top những dữ liệu được truy xuất nhiều nhất ra một cơ sở dữ liệu riêng. Khi có yêu cầu truy xuất dữ liệu thì trước tiên ta kiểm tra xem dữ liệu cần tìm có tồn tại trong bảng tạm hay không, nếu không thì mới đi tìm kiếm trong cơ sở dữ liệu gốc. Bởi vì chúng ta đã lựa chọn top những dữ liệu có tần suất truy cập nhiều nhất để cho vào bảng tạm nên xác suất để dữ liệu cần tìm được tìm thấy trong cơ sở dữ liệu tạm là rất cao. Điều này giúp việc truy xuất dữ liệu được thực hiện nhanh chóng hơn rất nhiều.

Một vài lưu ý khi sử dụng cache đó là các công nghệ dùng cho cache database thường là các on-memory database, vì vậy việc đảm bảo tính toàn vẹn và thống nhất của dữ liệu là rất quan trọng. Ngoài ra việc chọn dữ liệu nào để cache, dữ liệu nào không cần thiết cũng là một điều quan trọng ảnh hướng đến hiệu suất caching. Bằng một cách nào đó ta chỉ chọn cache những dữ liệu hiếm khi được dùng tới trong khi những dữ liệu được truy cập thường xuyên lại không được cache thì lúc đó hiệu năng hệ thống còn tệ hơn lúc không có cache.
Ngoài cache database, ta còn một khái niệm khác là Content Delivery Network (CDN). CDN cũng là một dạng caching, nhưng thay vì cache dữ liệu ứng dụng thì CDN thường chỉ dùng cache các static file như hình ảnh, HTML, Javascript, CSS,.. Cách thức hoạt động của CDN tương tự như cache, nhưng các hệ thống lớn thường sử dụng CDN của các bên thứ ba. Đó là những hệ thống CDN rất lớn được đặt đặt trên toàn cầu. Việc sử dụng các CDN này giúp giảm thời gian tải trang một cách đáng kể, bởi với hệ thống CDN rộng khắp, hệ thống dễ dàng tìm thấy server gần nhất theo khu vực địa lý của bạn. Ta cũng có thể áp dụng ý tưởng tương tự cho các cụm server và database. Thay vì đặt tất cả các server ở một nơi duy nhất thì việc đặt các cụm server ở nhiều nơi khác nhau sẽ hiệu quả hơn rất nhiều. Khi đó, load balancer ngoài việc điều hướng theo tải lượng của node thì cần phải có thêm tính năng geo routing để giúp điều hướng user đến server gần nhất theo vị trí địa lý.
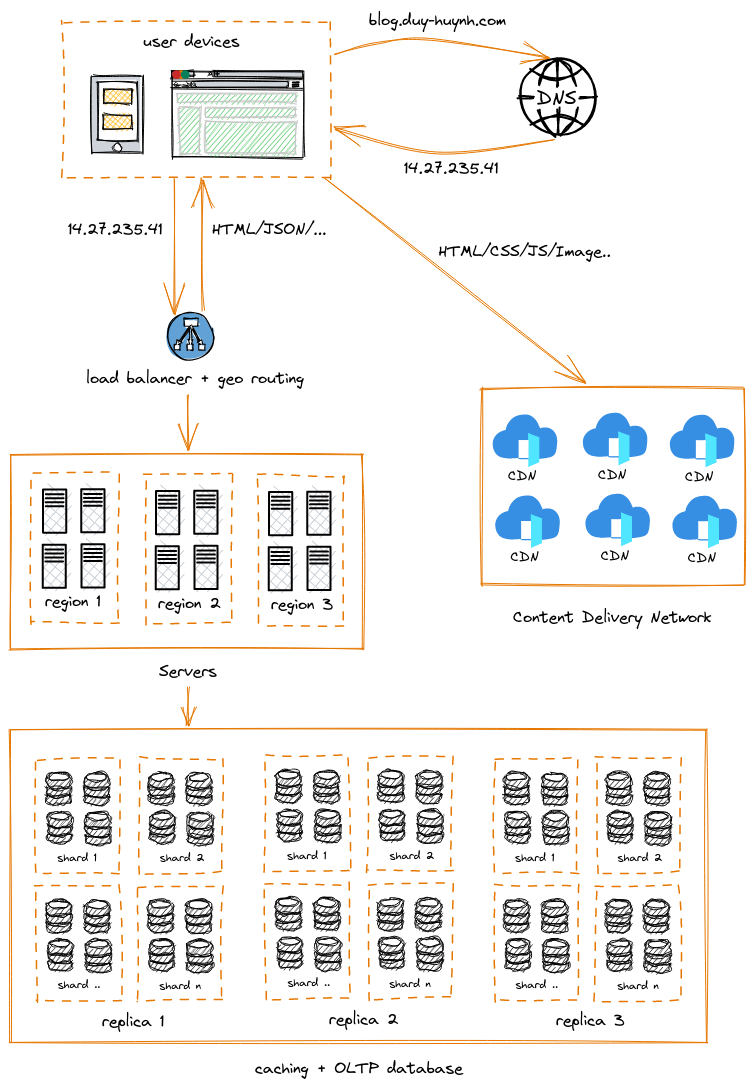
Bấy nhiêu là đủ cho một ví dụ cơ bản về ứng dụng vừa có khả năng đáp ứng lượng lớn người dùng vừa đủ linh hoạt để mở rộng khi cần thiết. Ngoài ra, ở những hệ thống yêu cầu xử lý nghiệp vụ phức tạp hơn thì chúng ta vẫn còn nhiều thành phần quan trọng chưa nói đến. Tuy nhiên, điều quan trọng nhất khi thiết kế một hệ thống không phải là phải ước lượng được tải lượng tối đa và thiết kế một hệ thống hoàn chỉnh ngay từ ban đầu. Mà là phải thiết kế một hệ thống đủ linh hoạt để mở rộng khi cần thiết và cần có lộ trình phát triển cụ thể để tối ưu hóa chi phí, công năng theo tốc độ phát triển của business.