The Evolution of Data Platform Architectures

In the ever-evolving landscape of data management, selecting the right data platform architecture is crucial for any organization aiming to leverage data as a strategic asset. Understanding the historical context and the evolution of various data architectures can help businesses identify the best fit for their specific needs. This post explores the journey of data platform architectures, highlighting their key features, benefits, and challenges.
1. Relational Warehouse (1984)
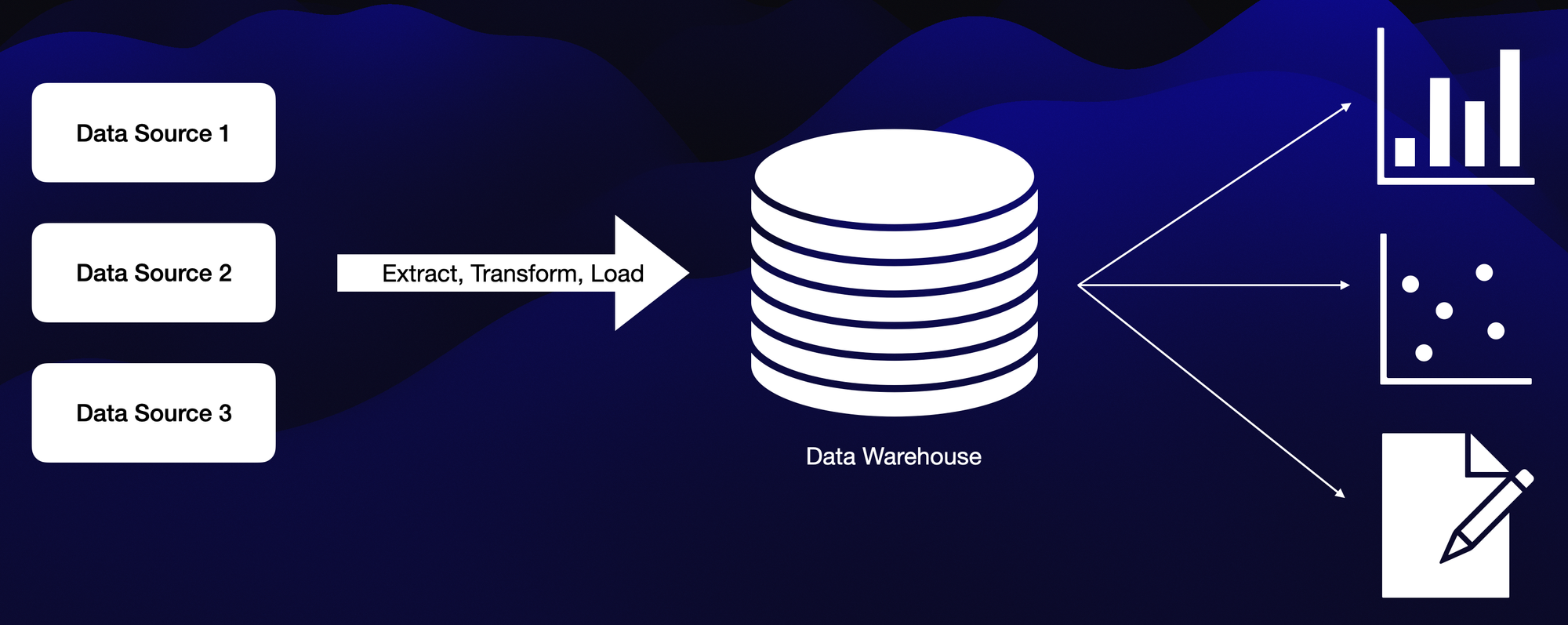
Key Features:
- Centralized Structured Data: A hub for large volumes of structured data from diverse sources.
- Relational Data Model: Organizes data into tables with rows and columns, leveraging SQL for data manipulation.
Benefits:
- Single Source of Truth: Consolidates data from multiple sources, ensuring consistency.
- Data Integrity and Quality: Enforces schema constraints for reliable decision-making.
- Transactional Processing: Optimized for performance with ACID guarantees.
Challenges:
- Complexity and Cost: Requires specialized expertise and significant investment.
- Limited Flexibility: Not suitable for all types of analysis, necessitating additional tools.
- Security Risks: Centralizing sensitive data increases the risk of breaches.
2. Data Lake (2010)
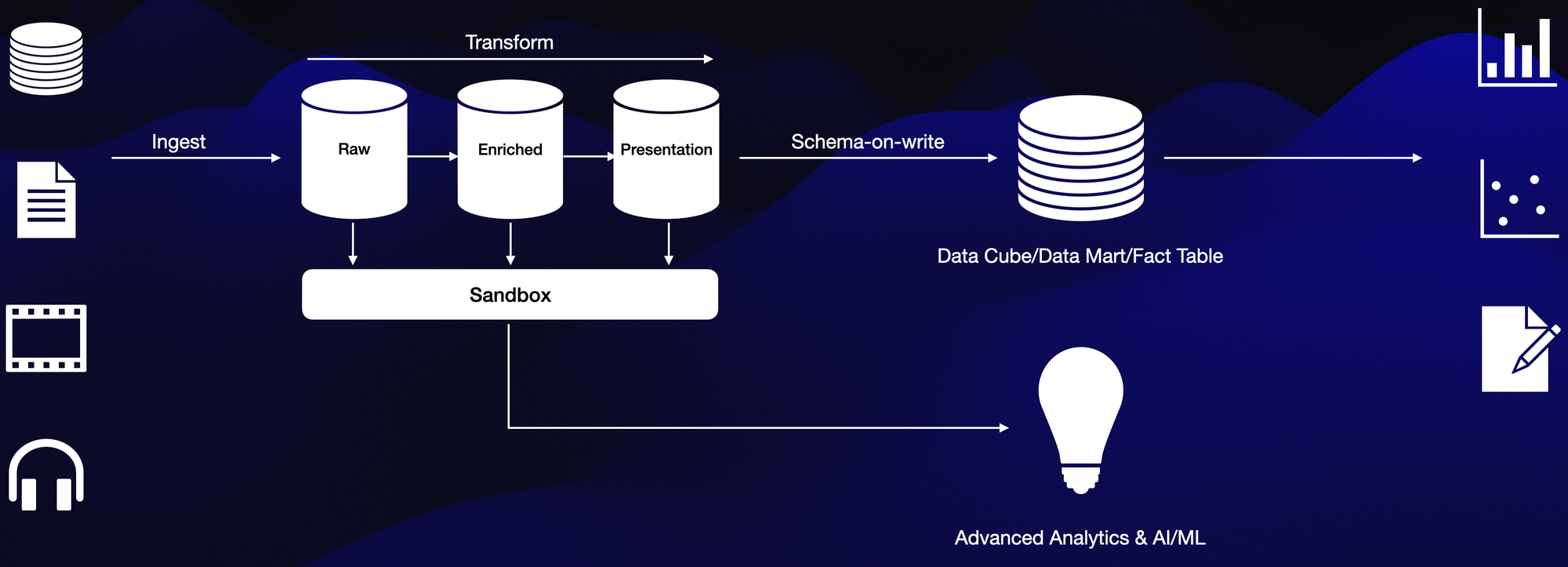
Key Features:
- Centralized Repository: Stores all data in its raw form, irrespective of type.
- Flexibility and Scalability: Easily scales with data growth, supporting advanced analytics and machine learning.
Benefits:
- Cost-Effective: Utilizes low-cost storage solutions.
- Support for Advanced Analytics: Facilitates data scientists in deriving insights from raw data.
Challenges:
- Complex Management: Without proper governance, can turn into a "Data Swamp."
- Quality and Consistency: Raw data may lead to inconsistencies if not managed properly.
- Performance Issues: Large volumes can slow down complex queries.
3. Modern Data Warehouse (2016)
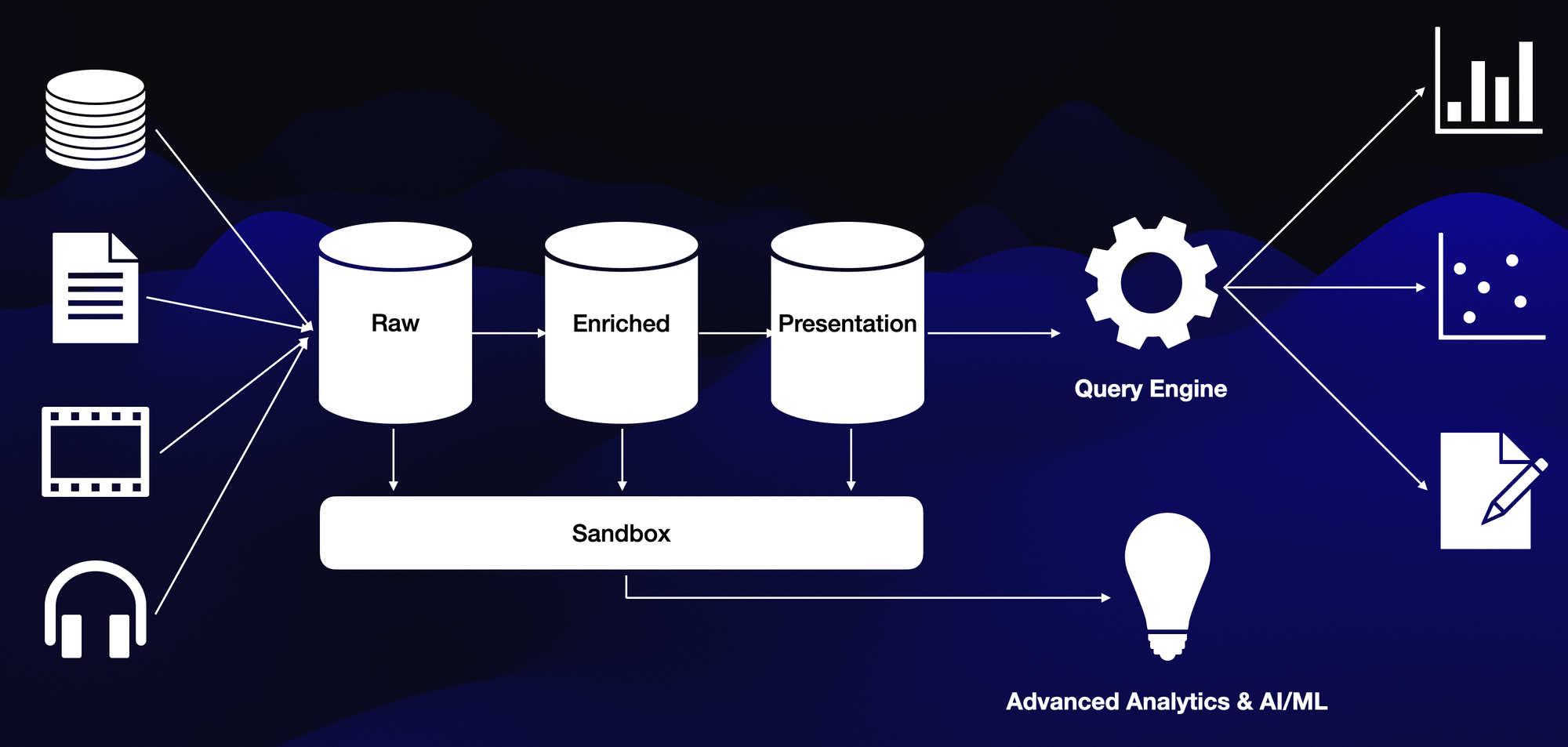
Key Features:
- Hybrid Architecture: Combines traditional data warehouse benefits with data lake storage.
Benefits:
- Broad Data Source Support: Handles structured, semi-structured, and unstructured data.
- AI/ML Integration: Supports advanced analytics and machine learning.
- Cost-Effective Storage: Economically scalable, combining data lake storage with efficient retrieval.
Challenges:
- Complexity: Intricate setup and management.
- Data Duplication: Replication between data lake and warehouse can lead to redundancy.
- Data Staleness: Risk of outdated data affecting real-time analytics.
4. Data Lakehouse (2020)
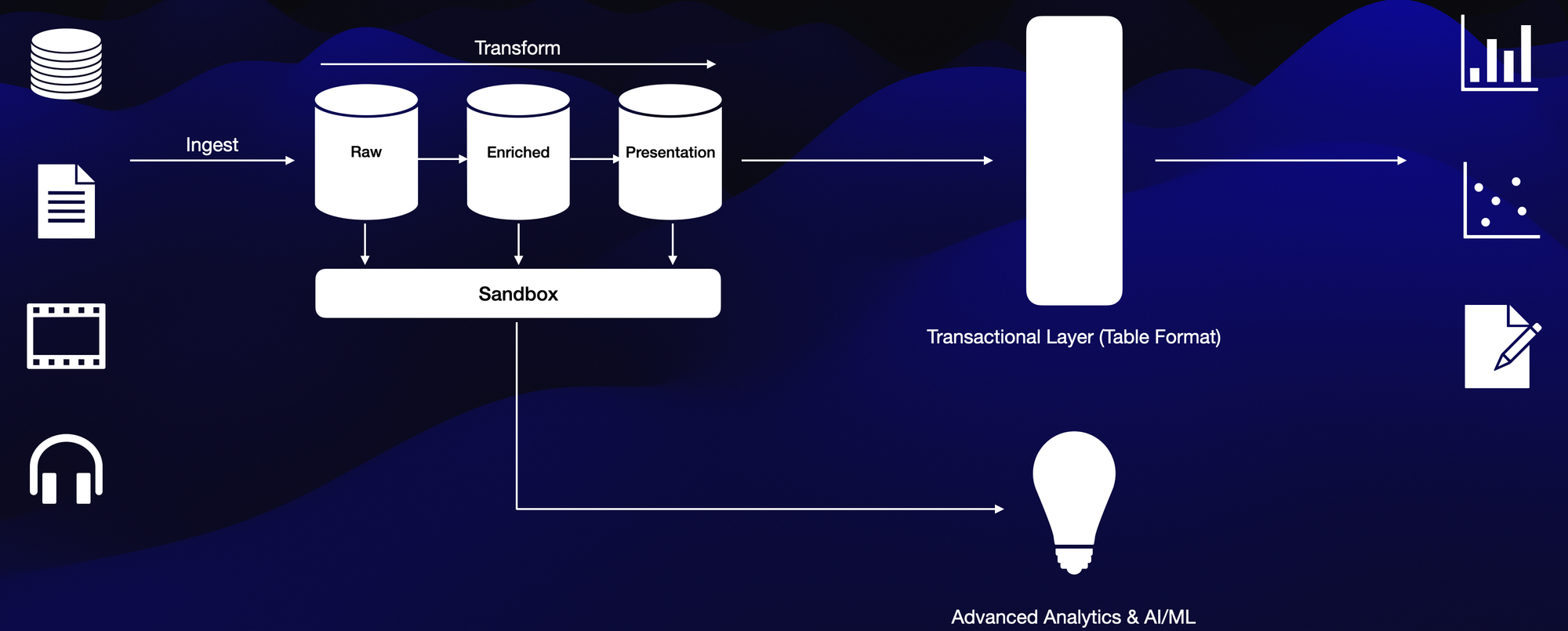
Key Features:
- Unified Storage: Combines data lake storage with relational warehouse features using a transactional layer.
Benefits:
- Reliability: Eliminates consistency issues from syncing data lakes and warehouses.
- Real-Time Data: Reduces staleness with immediate data availability.
- Cost-Effectiveness: Maintains a single copy of data, reducing costs.
- Simplified Governance: Streamlines data management and compliance.
Challenges:
- Technical Maturity: Newer technology with evolving ecosystems.
- Performance Optimization: Balancing performance for varied workloads is challenging.
- Query Complexity: Requires engineering for complex queries.
5. Data Fabric (2019)
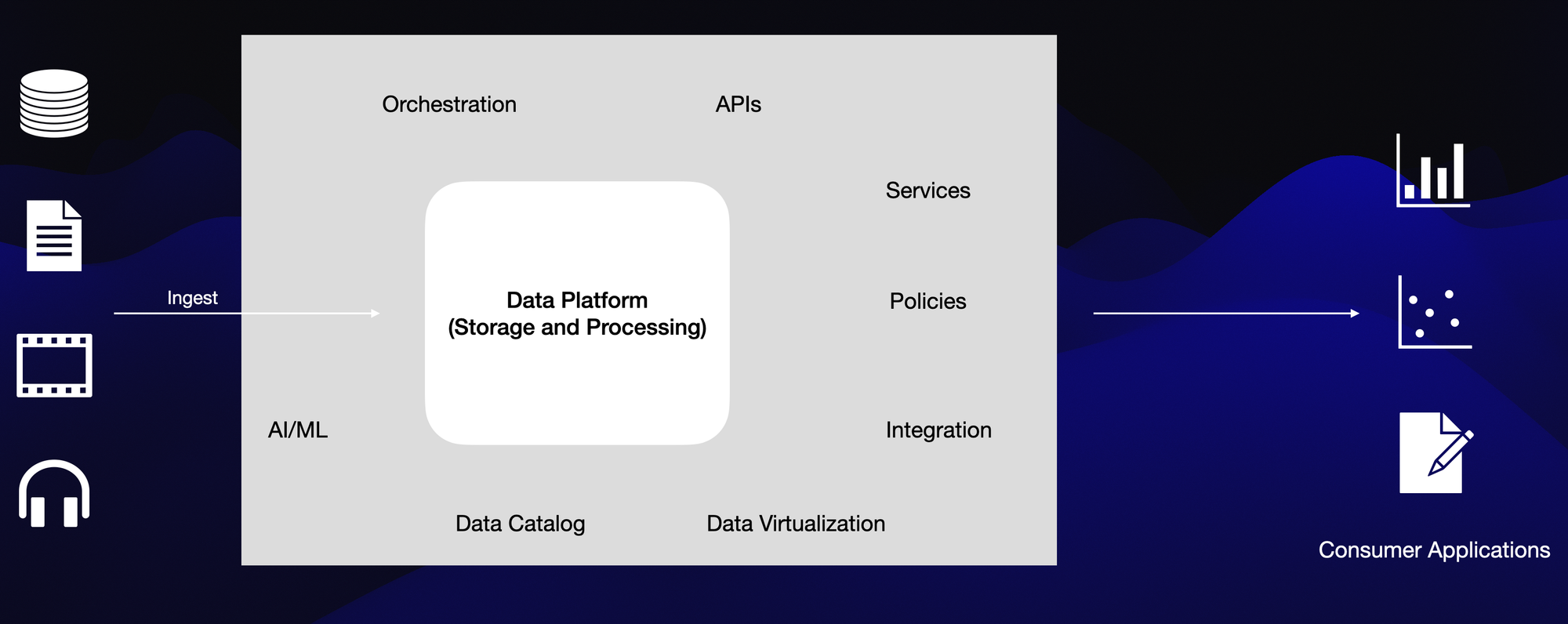
Key Features:
- Integrated Layer: Unifies disparate data systems with embedded governance and security.
Benefits:
- Data Access Policies: Ensures secure and controlled data access.
- Master Data Management: Maintains consistent and accurate data.
- Data Virtualization: Provides real-time access to source data without traditional ETL processes.
Challenges:
- Cost and Resource Intensive: Transitioning from monolithic systems can be expensive.
- Complex Operation: More difficult to operate and troubleshoot.
6. Data Mesh (2020)
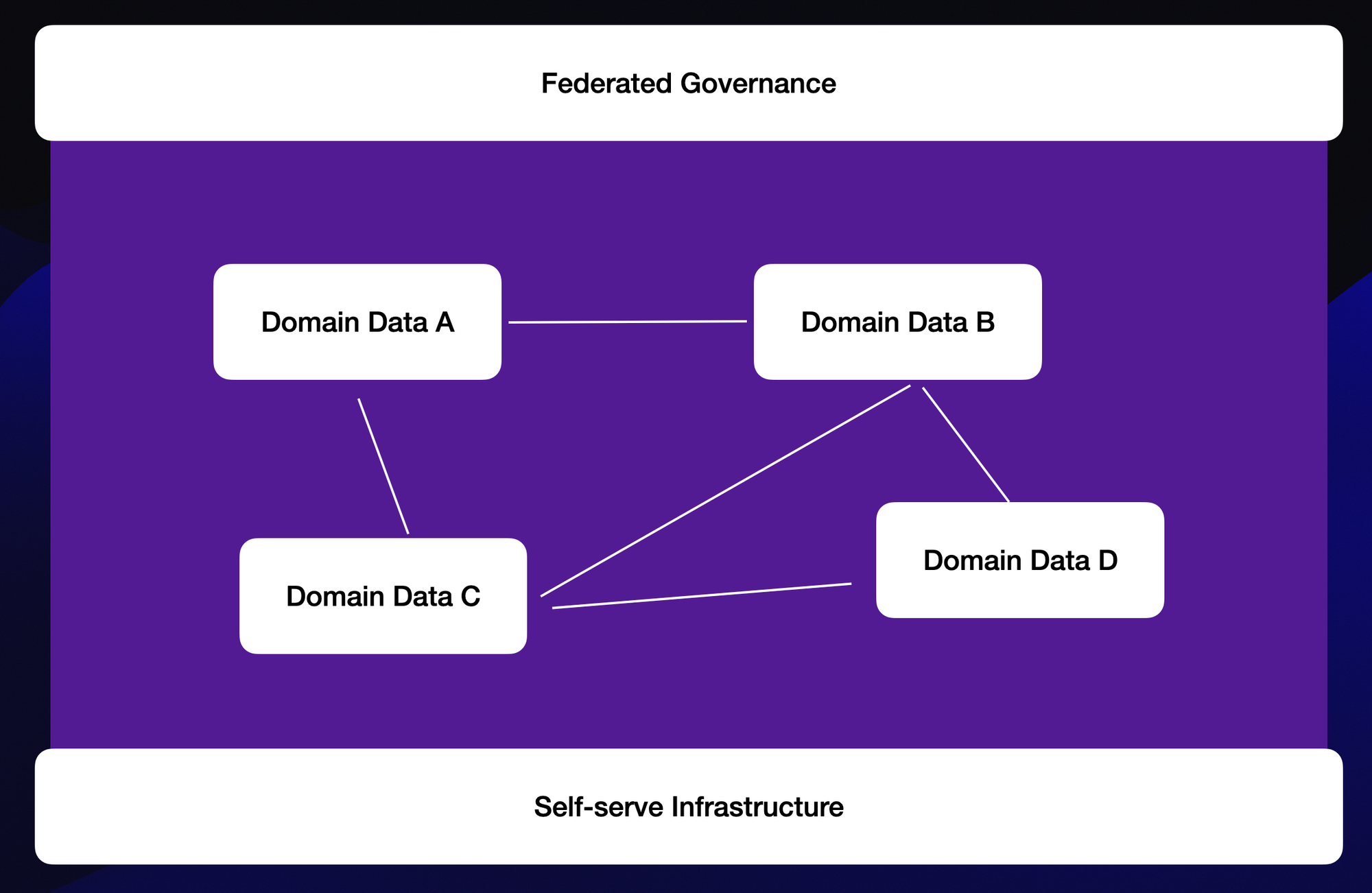
Data Mesh is a conceptual framework rather than a specific technology. It focuses on driving a shift in organizational structure and culture within enterprises.
Key Features:
- Decentralized Architecture: Focuses on domain ownership, data as a product, self-service infrastructure, and federated governance.
Benefits:
- Scalability: Suitable for large enterprises with complex data ecosystems.
- Optimized Data Ownership: Domain teams manage data, enhancing relevance and accuracy.
Challenges:
- Not a Quick Solution: Building a data mesh is complex and time-consuming.
- Philosophical and Conceptual Issues: Variations in understanding and interpreting what a data mesh is can lead to confusion and misalignment.
- Maintaining Consistency: Hard to maintain a single source of truth.
- Organizational Change: Requires significant shifts in structure and culture.
Choosing the Right Architecture
Selecting the right data platform architecture depends on your organization’s specific needs, data maturity, and goals.
- Modern Data Warehouse: Ideal for businesses handling smaller data volumes with familiarity in relational data warehouses.
- Data Lakehouse: A middle-ground solution recommended until its limitations are met.
- Data Fabric: Suited for businesses integrating diverse data sources.
- Data Mesh: Best for large, domain-oriented companies dealing with scalability challenges.
Understanding the evolution and features of each architecture enables informed decisions, aligning data strategy with business objectives and ensuring the most effective use of data as a strategic asset.