System Performance

Building a system that can handle large amounts of traffic and respond in a responsible time is the eventual goal of any system design problem. Before digging into the trick and specific design pattern, let's talk about what is the performance issue for a system first.
Response Time
When talking about performance, everyone might immediately think about the response time of the system. Indeed, this stands as one of the most critical aspects of a robust system. However, it's not merely a question of speed; it's also about efficiency. Let's break down the critical formula:
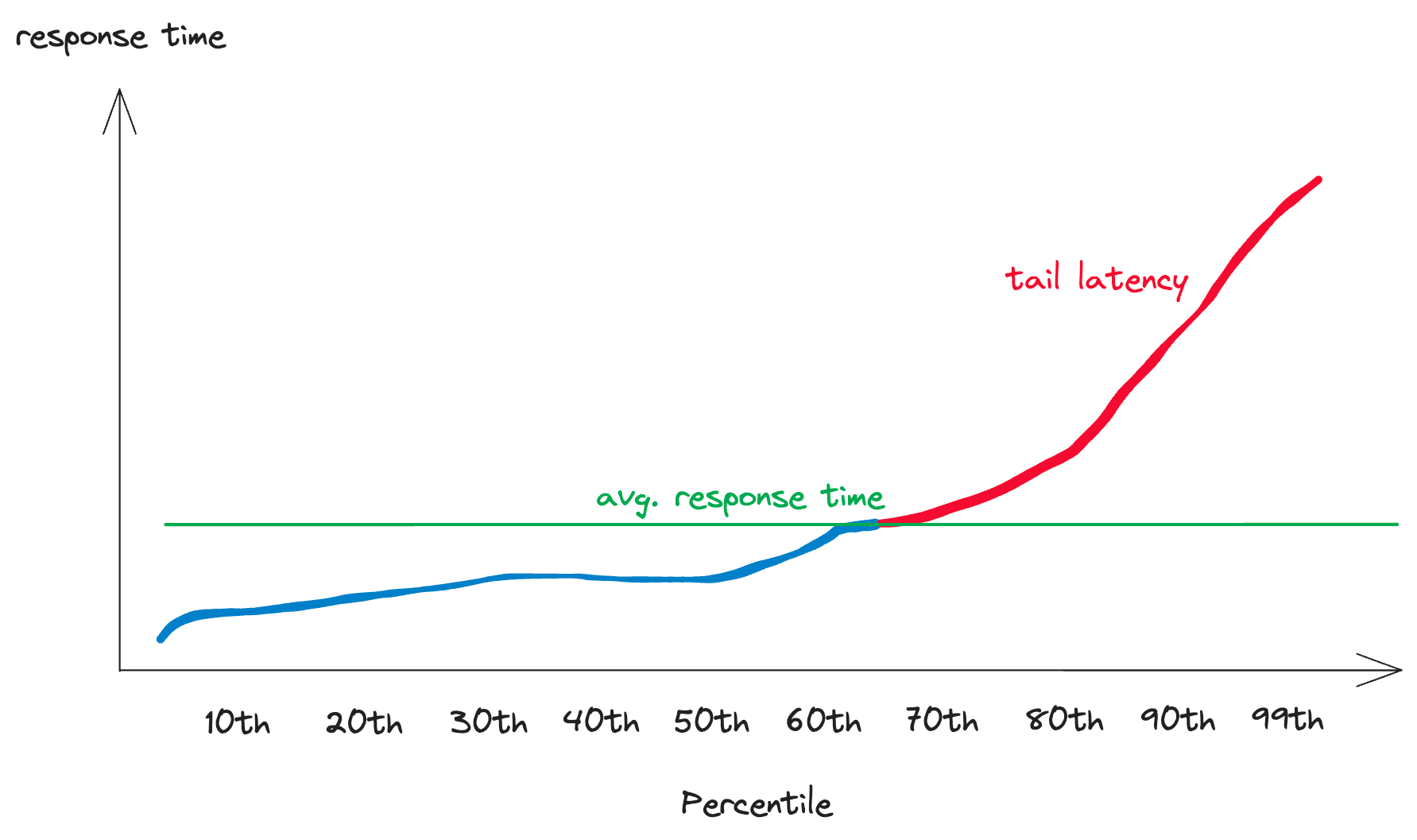
Response time is the total time taken to respond to a request. This includes Processing Time (the actual time to execute a request) and Latency (the delay incurred in the communication of the request). To measuring response time, you can build a response time distribution and then you can create a response time distribution and then calculate statistical figures like the average, median, or more. Nevertheless, the most widely used metric for discussing response time is the top percentile. For instance, TP99 = 100ms signifies that a certain percentage of incoming requests are handled within 100ms.
Using top percentile (TP) can help you better measure how fast the overall system can work with an amount of traffic.
Another thing that should be counted is tail latency. Thanks to percentile distribution, we can see how the tail latency curve visually present. In simple term, shorter tail latency mean better system. For more concise, the percentile distribution has a point that if the traffic surpasses this number, the response time will be increased drastically.
Throughput
Throughput quantifies the number of transactions a system can process per unit of time. It’s a raw figure indicating the system’s capacity. High throughput, coupled with low response time, is the hallmark of a high-performance system. This aspect is crucial for system that deals with large amounts of data payload. This number show how many data/request that the system can process concurrently. Consider a logging system responsible for storing all log data generated by the entire system—the throughput metric helps identify potential bottlenecks in handling thousands to millions of transactions in the database.
Performance Degradation
As we talk about tail latency, this is one of the reasons that might lead to performance degradation. Performance degradation is the issue when the performance of the whole system is degraded as the load increases. There are several potential reasons that we might encounter as below:
- High CPU utilization
- High memory consumption
- An abundance of I/O operations
- Exceeding database connection capacity
- ....
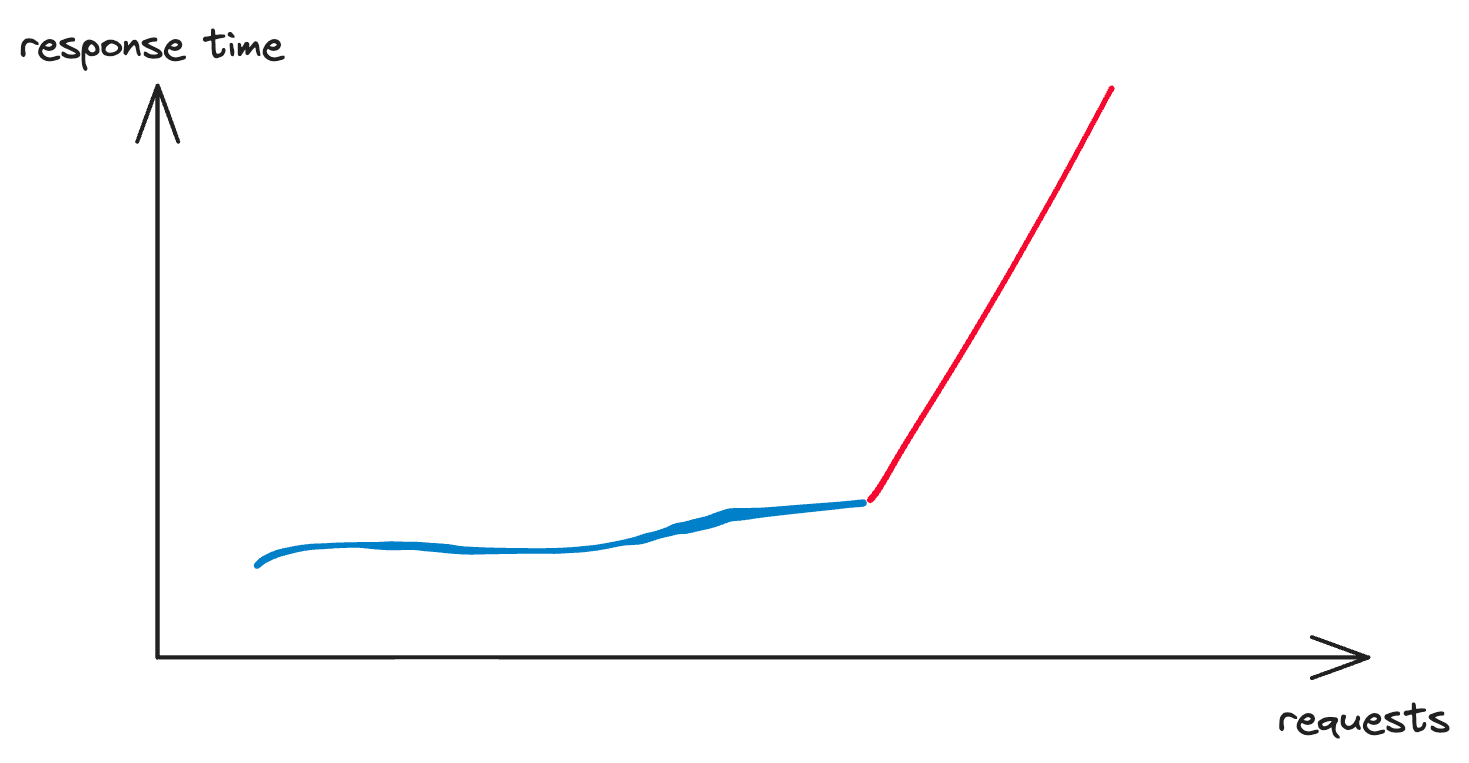
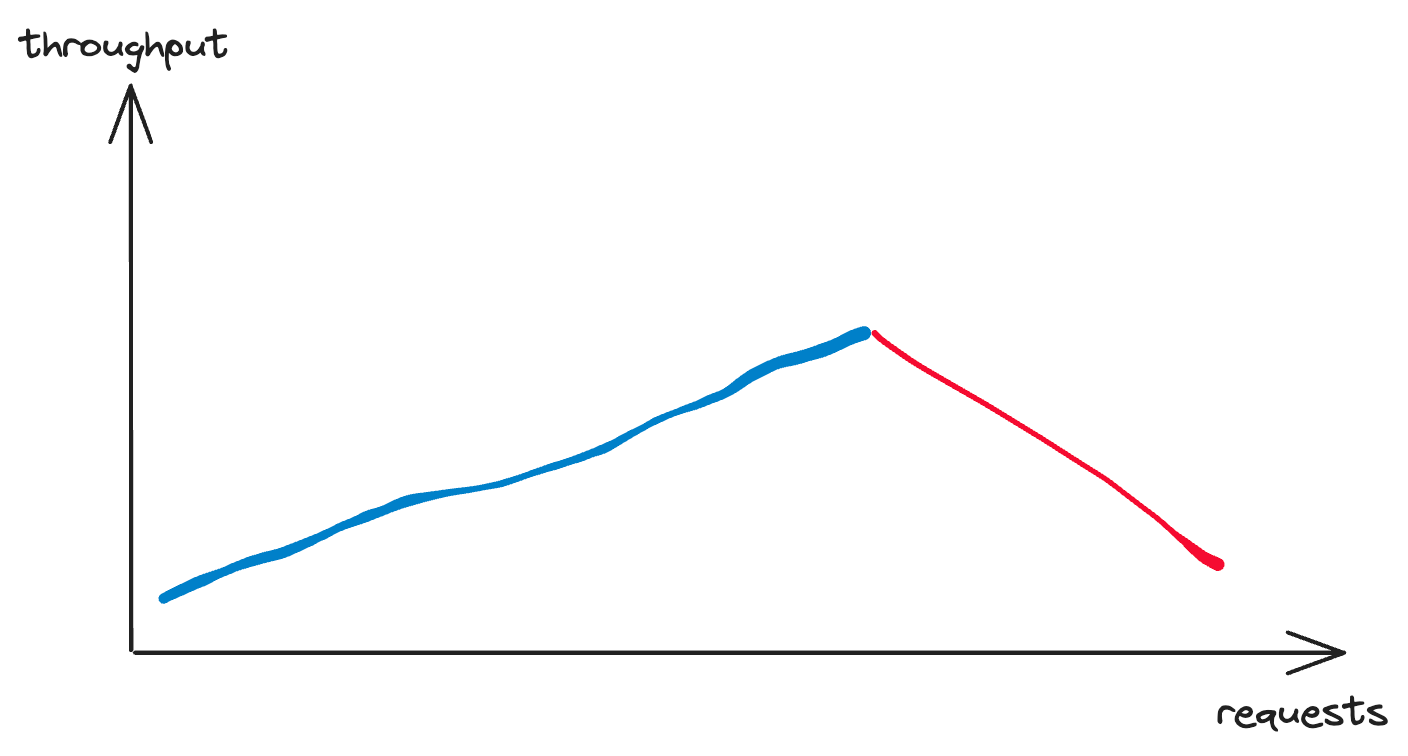
Preventing performance degradation and ensuring reliable service delivery even under increasing traffic is the hallmark of a proficient system design practitioner. This will be the central theme of discussion throughout this series.
In our journey to master the art of system design, we'll unravel the intricate techniques and strategies to ensure that your systems not only handle immense traffic but do so with lightning speed, unwavering efficiency, and uninterrupted reliability. Stay tuned for more insights into creating high-performance systems.